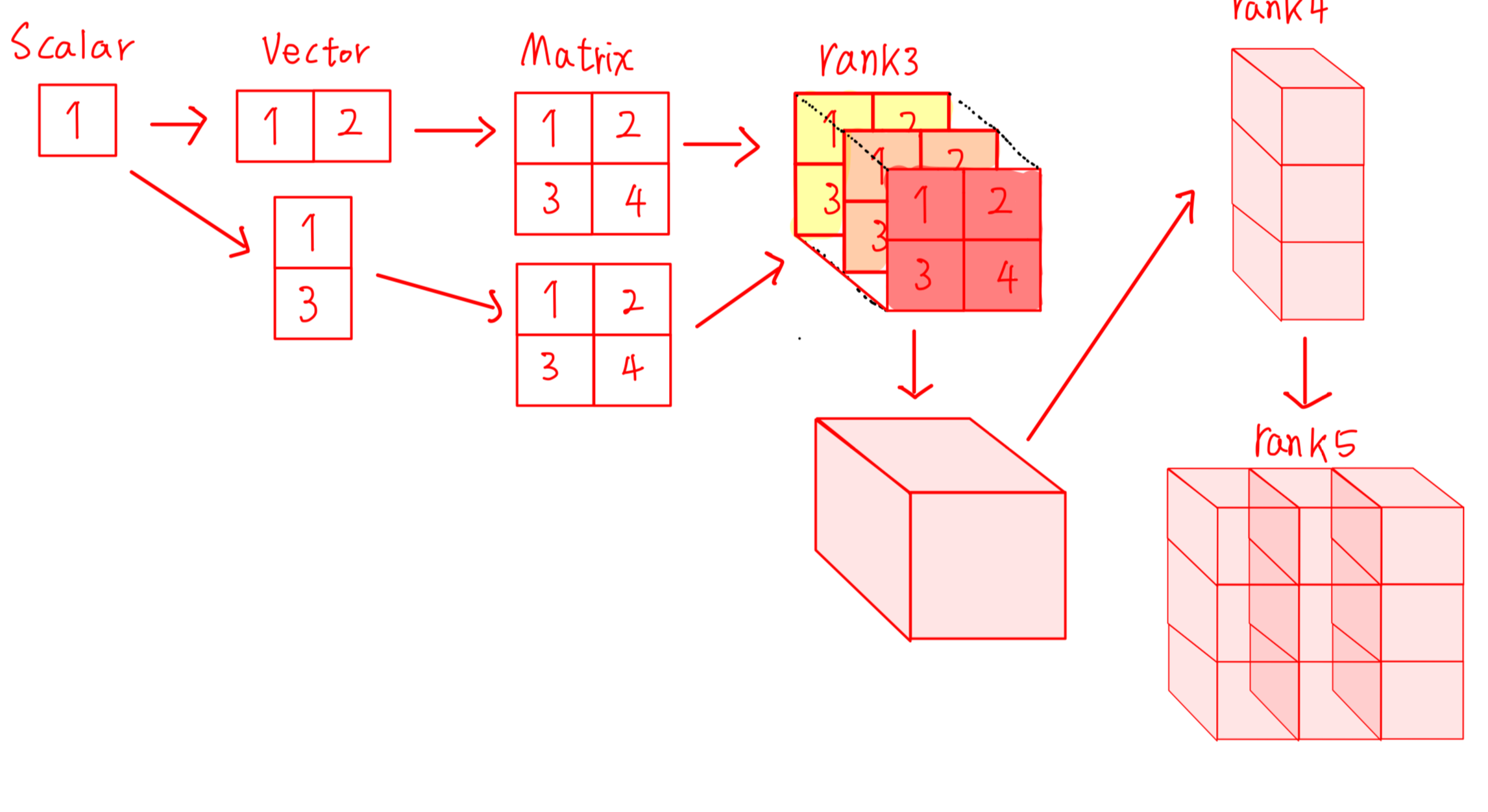
목차 텐서플로우 텐서플로는 구글의 어느 한 팀에 의해 공개된 대표적인 머신러닝 라이브러리이다. 이는 파이썬뿐만 아니라, 다양한 언어를 사용하고 모델을 개발하고 배포할 수 있는 다양한 도구를 지원한다. 그리고 텐서플로우는 딥러닝 연산을 처리하는 라이브러리로서 텐서라고 불리는 데이터를 계산 그래프 구조를 통해 흘려가면서 복잡한 행렬 연산을 처리하게 된다. 이번에는 파이썬 언어를 이용해 공부해보자 한다. 텐서플로우 자료구조 텐서플로우는 파이썬 자료형 값들을 텐서플로우 자료구조인 텐서(Tensor)로 변환되어 처리하는데.. 0차원 텐서인 스칼라, 1차원 벡터, 2차원 행렬, 3차원 텐서, 4차원 텐서..... 차수가 1씩 증가함에 따라 데이터 구조가 확장된다. 여기서 차수는 차원의 수를 말하는 것이며 텐서를 구..