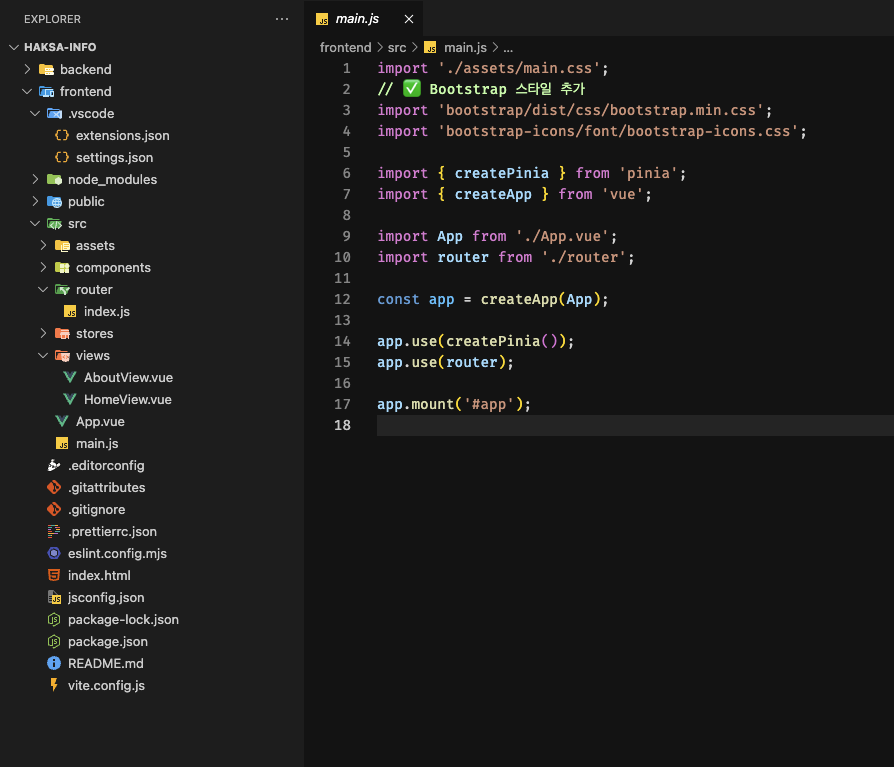
목차1: Vue Router 설정 (페이지 연결)📁 src/router/index.js 수정import { createRouter, createWebHistory } from 'vue-router';// 각 페이지 컴포넌트 importimport HomeView from '../views/HomeView.vue';import NoticeView from '../views/NoticeView.vue';import TranscriptView from '../views/TranscriptView.vue';import TuitionView from '../views/TuitionView.vue';import ScheduleView from '../views/ScheduleView.vue';const route..