목차
해싱 Hashing
해싱은 키값을 비교하여 찾는 검색 방법이 아니라 산술적인 연산으로 키가 있는 위치를 계산하여 바로 찾아가는 방식이다.
키값을 원소 위치로 변환하는 함수를 해시 함수 Hash Function, 해시 함수로 계산된 주소 위치에 항목을 저장한 표를 해시 테이블 Hash Table이라고 한다.
이러한 해싱을 이용해서 유용하게 활용이 가능한 곳에는....
- 데이터 무결성 확인: 해시 함수는 입력 데이터에 대해 고정된 크기의 해시 값을 생성한다. 이는 데이터의 무결성을 확인하는 데 사용될 수 있고 데이터가 변경되었을 때 해시 값도 변경되기 때문에 변경 여부를 쉽게 감지할 수 있다.
- 암호학: 해시 함수는 암호학에서도 중요한 역할을 하는데, 패스워드 저장 및 검증, 디지털 서명, 메시지 인증 등에서 사용된다.
- 분산 데이터베이스: 해싱은 데이터를 여러 노드에 분산시키는 데에도 활용되며 해시 함수를 사용하여 각 데이터를 특정 노드에 할당함으로써 분산 데이터베이스에서 효율적으로 데이터를 관리할 수 있다.
- 블록체인: 블록체인에서는 해시 함수가 블록의 고유 식별자로 사용되는데, 각 블록의 해시 값은 이전 블록의 일부 정보를 포함하므로 블록체인에서 데이터의 변경 여부를 확인하는 데 사용된다.
- 캐싱: 해시 함수를 이용하여 캐시를 구현할 수 있다. 해시 값을 사용하여 이전에 계산된 결과를 빠르게 검색하고, 동일한 입력에 대한 결과를 캐시에서 가져오는 것으로 성능을 향상할 수 있다.
- 고유한 식별자 생성: 해시 함수를 사용하여 고유한 식별자를 생성할 수 있고, 이는 데이터베이스의 키 생성이나 개체 식별에 유용할 수 있다.
- 자료구조 구현: 해싱은 해시 테이블과 같은 자료구조를 구현하는 데에도 사용되며, 이를 통해 데이터를 효율적으로 삽입, 삭제 및 검색할 수 있다.
해싱 검색은 키 값에 대해서 해시 함수를 이용하여 키값을 계산하여 주소를 구하고, 구한 주소에 해당하는 해시 테이블로 이동하여 찾는 항목이 있으면 검색 성공 찾는 항목이 없다면 검색 실패가 된다.
예를 들어 도서관에서 책을 검색하는 것이다.
그러면 해시 테이블(버켓)은 어떻게 구성하느냐? 버켓은 n개와 슬롯 m개로 구성하는데, 해시 함수에 의해 계산된 주소가 버켓의 주소가 되고 이때 사용하는 해시 함수는 0 ~ n-1 사이의 버켓 주소만을 만들어야 한다.
해싱 관련 용어
- 동거자 (Synonym):
- 동거자는 해시 함수에 의해 동일한 해시 값으로 매핑되는 두 개 이상의 키를 가리킵니다. 동거자가 발생하면 충돌이 발생한 것이다..
- 쉽게 말해 모든 키값이 고르게 사용되어서 이상적인 버켓이 형성이 되면 좋지만 모든 키값이 고르게 사용되는 것이 아니다.
또한 키값의 수만큼 버켓을 많이 만들면 메모리 공간만 낭비가 된다. 따라서 버켓 수를 줄이고 같은 버켓 안에 여러 개를 두기도 한다. 이외에도 다른 경우도 있겠지만 서로 다른 키값을 가지지만 해시 함수에 의해서 같은 버켓에 저장된 값을 동거자라한다.
- 충돌 (Collision):
- 충돌은 서로 다른 키가 동일한 해시 값으로 매핑되는 상황을 의미한다. 모든 해시 함수는 유한한 범위의 출력을 갖기 때문에 서로 다른 입력에 대해 동일한 해시 값이 생성될 수 있고, 충돌이 발생하면 일반적으로 충돌에 대한 해결책이 필요하다.
- 쉽게 말해 키 값이 서로 다름에도 불구하고 해시 함수에 의해 주어진 버켓 주소가 같은 경우를 충동이라고 한다.
하지만 충돌이 발생한다면 비어있는 버켓에 동거자 관계로 키값을 저장하면 되지만 만약 비어 있는 슬롯이 없다면
포화 버켓 상태로 다시 충돌이 발생해 오버플로우가 된다.
- 오버플로우
적재 밀도 (Load Factor):- 적재 밀도는 해시 테이블에서 현재 저장된 항목 수와 전체 버킷 수 간의 비율을 나타낸다. 일반적으로는 적재 밀도가 증가할수록 충돌이 발생할 가능성이 높아지기 때문에 적절한 적재 밀도를 유지하면 충돌을 최소화하고 해시 테이블의 효율을 높일 수 있다.
- 쉽게 말해 적재 밀도는 해시 테이블에 저장 가능한 키값의 개수 중에서 현재 해시 테이블에 저장되어 실제 사용되고 있는 키값의 정도를 나타낸다.
- 적재 밀도 = 실제 사용 중인 키값의 개수 / 해시 테이블에 저장 가능한 전체 키값의 개수
= 실제 사용 중인 키값의 개수 / (버켓 개수 X 슬롯 개수)
- 키값 밀도는 해시 테이블에서 저장된 실제 키의 수와 전체 해시 버킷의 수 간의 비율을 나타내는데, 높은 키값 밀도는 테이블의 공간을 효과적으로 활용하는 것을 의미한다.
- 쉽게 말해 키값 밀도는 사용 가능한 전체 키값 중에서 현재 해시 테이블에 저장되어 실제 사용되고 있는 키값의 개수 정도를 나타낸다.
- 키값 밀도 = 실제 사용 중인 키값의 개수 / 사용 가능한 키값의 개수
해시 함수
해싱 검색에서 가장 중요한 것은 키값의 위치를 계산하여 주는 해시 함수이다. 어떤 해시 함수를 사용하느냐에 따라 해싱 검색의 효율이 달라지는데 그러면 해시 함수를 구현하는 방법에는 무엇이 있을까?
중간 제곱 함수
중간 제곱 함수는 키값을 제곱한 결값에서 중간에 있는 적당한 비트를 주소로 사용한다.
제곱한 값의 중간 비트들은 대개 키의 모든 값과 관련이 있기 때문에 서로 다른 키값은 서로 다른 중간 제곱 함숫값을 갖는다.
키값이 2진수로 00110101 10100111일 때 중간 제곱 함수를 사용하여 주소를 구해 보면...
키값에 대한 2진수를 제곱한 결값에서 가운데 있는 8비트는 11101001이 된다. 그러면 11101001의
10진수 값 233이 해시 테이블의 버킷 주소가 된다.
00110101 10100111 x 00110101 10100111= 00001011001111101001001011110001
제곱 결값에서 주소로 사용하는 비트 수는 해시 테이블의 버킷 개수에 따라 결정된다. 버킷이 256개 있다면 버킷 주소는 0~255인 256개 값을 사용한다. 256(28) 개 값을 만들기 위해 필요한 최소 비트 수는 8비트이므로 제곱 결괏값에서 8비트를 주소로 사용한다.
제산 함수(가장 많이 사용)
제산 Division 함수는 나머지 연산자 mod (C에서는 % 연산자)를 사용하는 방법으로 키값 k를 해시 테이블 크기인 m으로 나눈 나머지를 해시 주소로 사용한다.
M으로 나눈 나머지 값의 범위는 0~(m-1)이 프로 해시 테이블의 인덱스로 사용할 수 있다. 해시 주소는 충돌이 발생하지 않고 고르게 분포하도록 생성되어야 하므로 키값을 나누는 해시 테이블 크기 m은 적당한 크기의 소수 Prime Number를 사용한다.
h (k) = k mod M
예를 들어, 테이블 크기가 100인 경우에는 101, 103, 107과 같은 소수를 선택하는 것이 일반적이라고 한다. 이렇게 소수를 사용하면 특정한 패턴이나 주기로 해시 값이 중복되는 것을 방지하고, 충돌이 발생할 확률을 줄일 수 있다고 한다.
승산 함수
승산 함수는 곱하기 연산을 사용하는 방법이다. 키값 k와 정해진 실수 a를 곱한 결과에서 소수점 이하 부분만을 테이블 크기 m과 곱하여 그 정수값을 주소로 사용한다.
"승산 함수"는 일반적인 용어로써, 문맥에 따라 다르게 사용될 수 있습니다. 하지만 가장 널리 사용되는 용어 중 하나는 "로지스틱 함수"를 가리키는 경우입니다.
접지 함수
접지 함수는 주로 키의 비트 수가 해시 테이블 인덱스의 비트 수보다 클 때 사용한다. 키값 k가 있을 때 해시 테이블 인덱스의 비트 수와 같은 크기로 분할한 후 분할된 부분을 모두 더하여 해시 주소를 만든 다. 이때 더하는 방법에 따라 이동 접지 함수와 경계 접지 함수로 나눌 수 있다.
- 이동 접지 함수
이동 접지 함수는 각 분할 부분을 이동시켜서 오른쪽 끝자리가 일치하도록 맞춘 뒤 더한다. 해시 테이블 인덱스가 세 자리이고, 키값 k가 12312312312인 경우에 이동 접지 함수를 이용하여 해시 주소를 구해 보면...
키값 k를 세 자리 크기로 분할하면 k ₁=123, k ₂=123, k ₃=123, k ₄=12가 된다.
분할하여 구한 키값들을 오른쪽 끝자리가 일치하도록 옮겨서 더한 값인 381이 인덱스 테이블의 주 소가 된다. - 경계 접지 함수
경계 접지 함수는 분할된 각 경계를 기준으로 접으면서 서로 마주 보도록 배치하고 더한다.
해시 테이블 인덱스가 세 자리이고, 키값 k가 12312312312인 경우에 경계 접지 함수를 이용하여 해시 주소를 구해 보면.....
키값 k를 세 자리 크기로 접으면k ₁=123, k ₂=321, k ₃=123, k ₄=21이 된다. 이렇게 구한 키값들을 오른쪽 끝자리가 일치하도록 자리를 맞추고 더한 값인 588이 인덱스 테이블의 주소가 된다.
숫자 분석 함수
숫자 분석 함수는 숫자에 대한 통계적인 분석을 수행하거나 특정 수학적 연산을 적용하는 함수를 의미하는데, 어려운 얘기는 무시하고,,
쉽게 말해 키값을 이루고 있는 각 자릿수의 분포를 분석하여 해시 주소로 사용한다. 각 키값을 적절히 선택한 진수로 변환한 후에 각 자릿수의 분포를 분석하여, 가장 편중된 분산을 가진 자릿수는 생략하고 가장 고르게 분포된 자릿수부터 해시 테이블 주소의 자릿수만큼 차례로 뽑아서 만든 수를 역순으로 바꾸어 사용한다.
진법 변환 함수
진법 변환 함수는 어떤 수를 한 진법에서 다른 진법으로 변환하는 함수를 의미한다. 예를 들어, 10진수를 2진수로 변환하거나 16진수로 변환하는 함수가 여기에 해당한다. 변환된 결과는 다른 진법에서 해당 숫자를 나타내는 표현이 된다.
비트 추출 함수
비트 추출 함수는 해시 테이블의 크기가 2 ᵏ일 때, 키값을 이진 비트로 놓고 임의의 위치에 있는 비트들을 추출하여 주소로 사용한다. 이 방법에서는 충돌이 발생할 가능성이 많으므로 테이블 일부에 주소가 편중되지 않도록 키값의 비트를 미리 분석하여 사용해야 한다.
해싱에서 오버플로우를 처리하는 방법은?
해시 테이블과 해시 함수를 잘 선택하여 오버플로가 발생하지 않도록 해야 하지만, 오버플로가 발생하 더라도 문제를 효율적으로 해결해야 한다. 오버플로를 해결하는 방법에는 충돌이 일어난 키값을 비어 있는 다른 버킷을 찾아 저장하는 선형 개방 주소법과 여러 항목을 저장할 수 있도록 해시 테이블의 구조를 변경하는 체이닝 방법이 있다.
선형 개방 주소법
선형 조사법 Linear Probing이라고도 하며 선형 개방 주소법에서 해시 함수로 구한 버켓에 빈 슬롯이 없어 오버플로우가 발생했다면 그다음 버켓에 빈 공간이 없는지 조사하고, 빈 슬롯이 있으면 키값을 저장하고 없으면 다시 그 다음 버켓을 조사하는 방식으로 오버플로우를 해결한다. 좋지 않은 방법이다.
해시 테이블의 크기가 5이고 제산 함수를 해시 함수로 사용하는 경우에 선형 개방 주소법을 사용하여 오버플로우를 처리하는 과정을 보면..
1. h(45) = 45 mod 5 = 0 -> 해시 테이블 0번에 키값 45 저장

2. h(9) = 9 mod 5 = 4 -> 해시 테이블 4번에 키값 9 저장
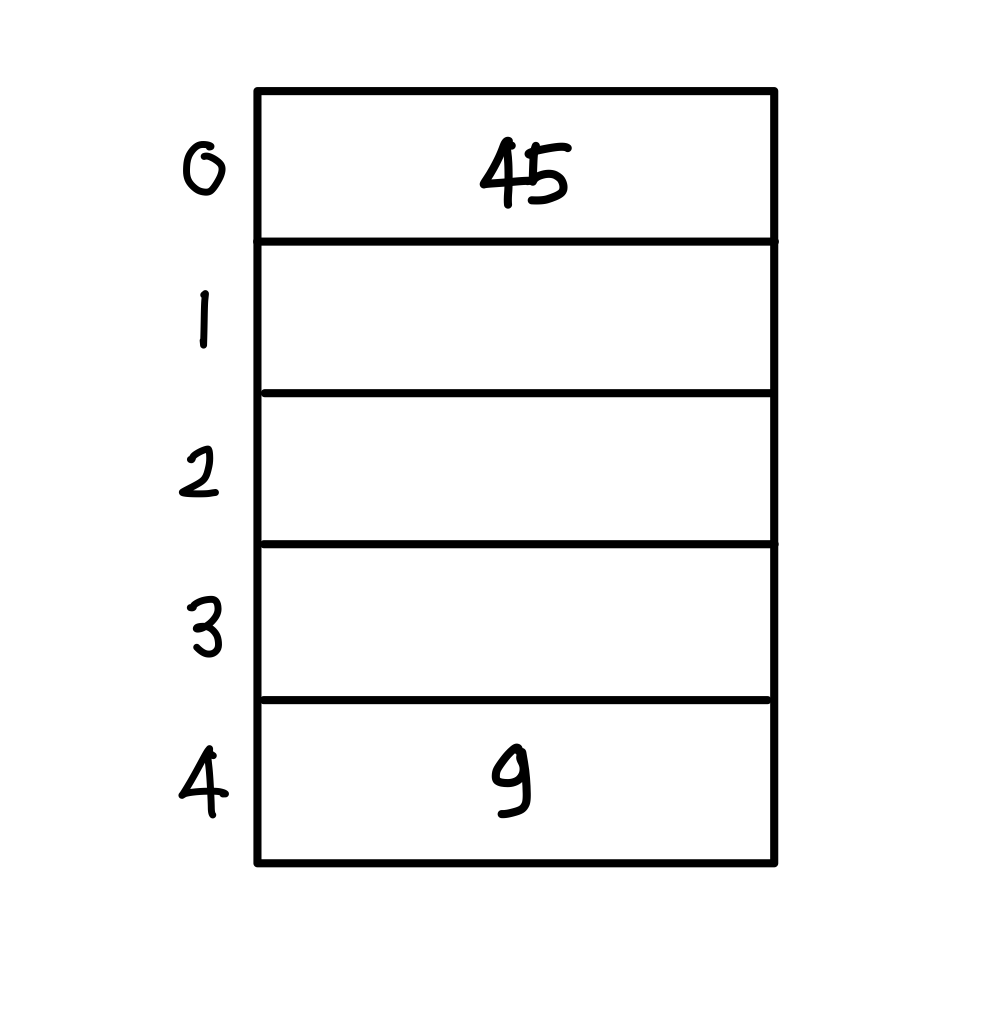
3. h(10) = 10 mod 5 = 0 -> 충돌 발생 -> 다음 버켓 중에서 비어 있는 버킷 1에 키값 10 저장
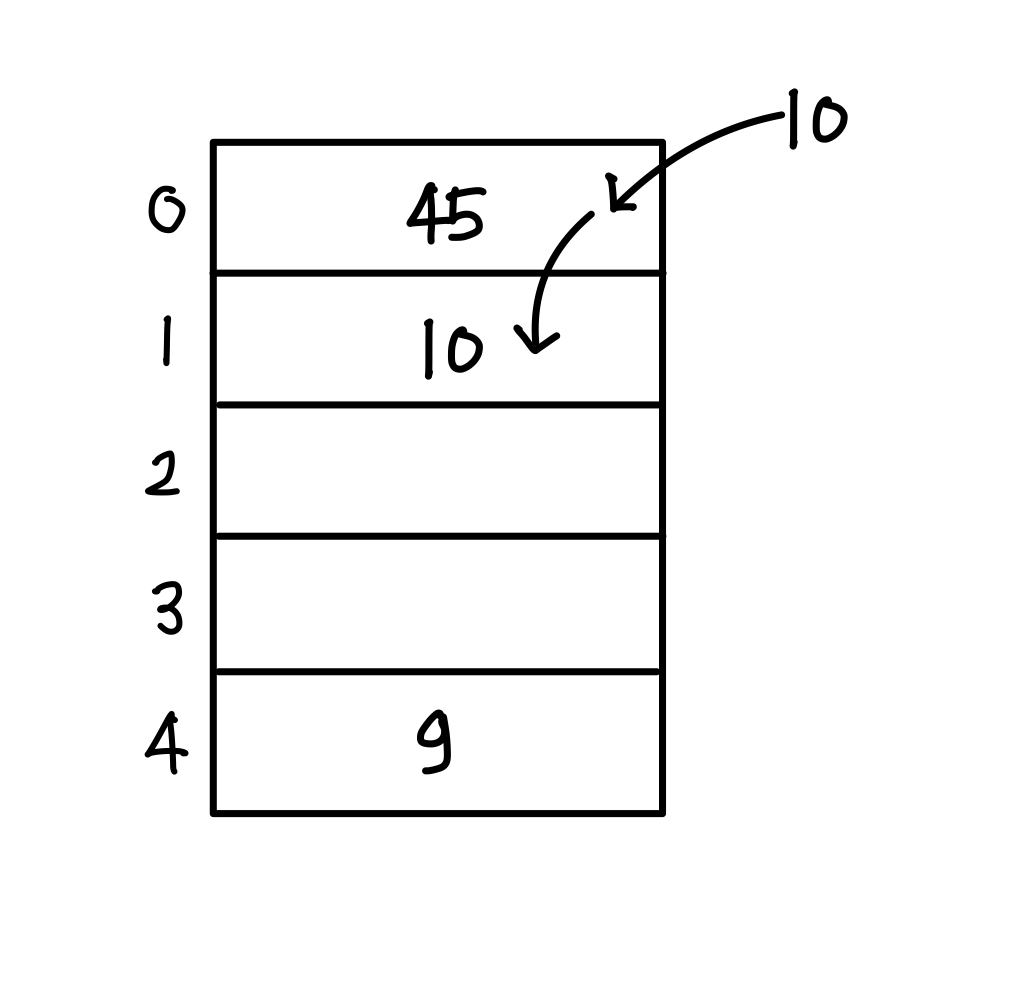
4. h(96) = 96 mod 5 = 1 -> 충돌 발생 -> 다음 버켓 중에서 비어 있는 버킷 2에 키값 96 저장
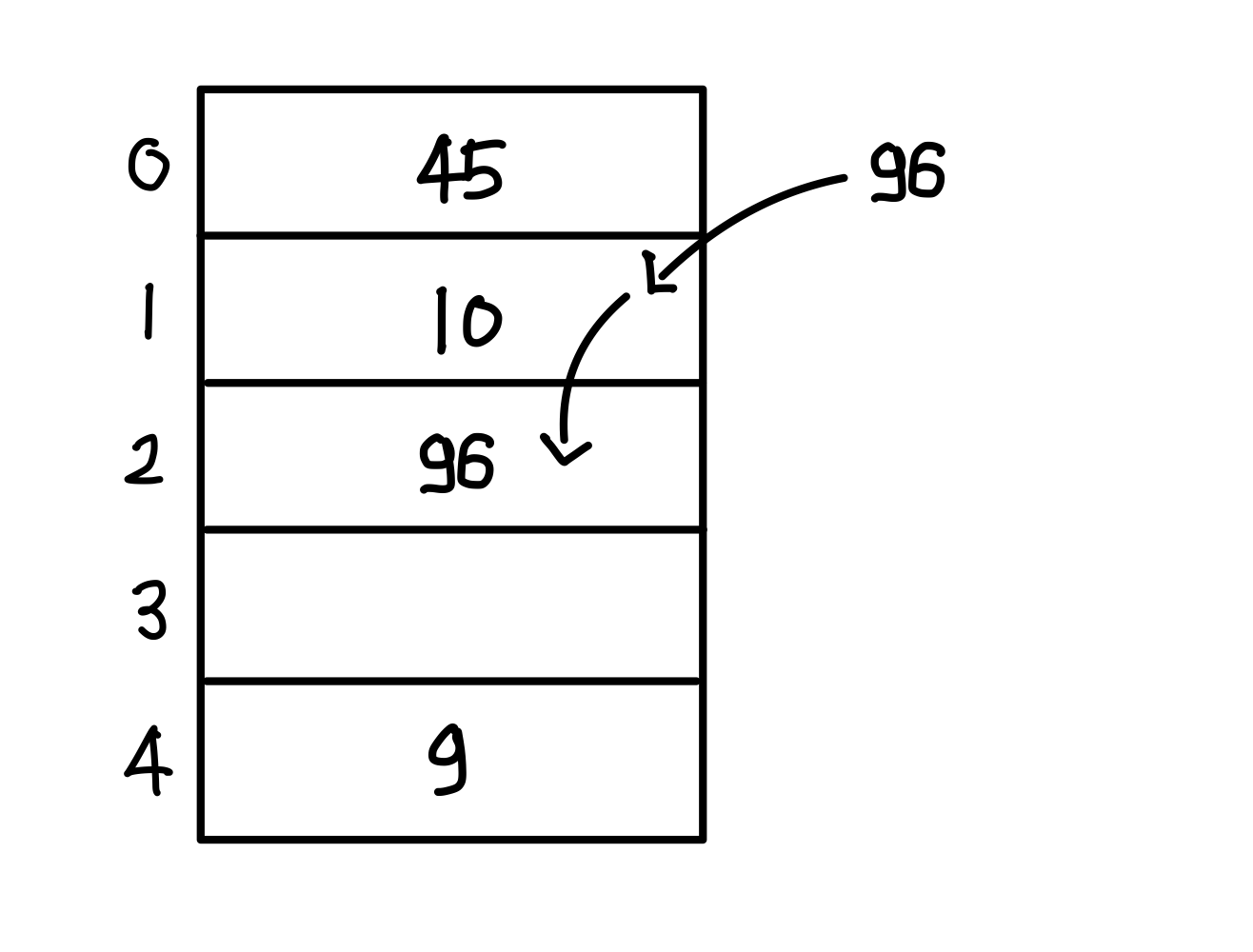
체이닝
체이닝은 해시 테이블의 구조를 변경하여 각 버켓에 하나 이상의 키값을 저장할 수 있도록 하는 방법으로 버켓에 슬롯을 동적으로 삽입하고 삭제하기 위해 연결 리스트를 사용한다. 각 버켓에 대한 헤드 노드는 1차원 배열이고, 슬롯은 헤드 노드에 연결 리스트 형태로 이어진다.
버켓 내에서 원하는 슬롯을 검색하려면 버켓의 연결 리스트를 선형 검색한다.
1. h(45) = 45 mod 5 = 0 -> 해시 테이블 0번에 노드를 삽입하고 키값 45를 저장
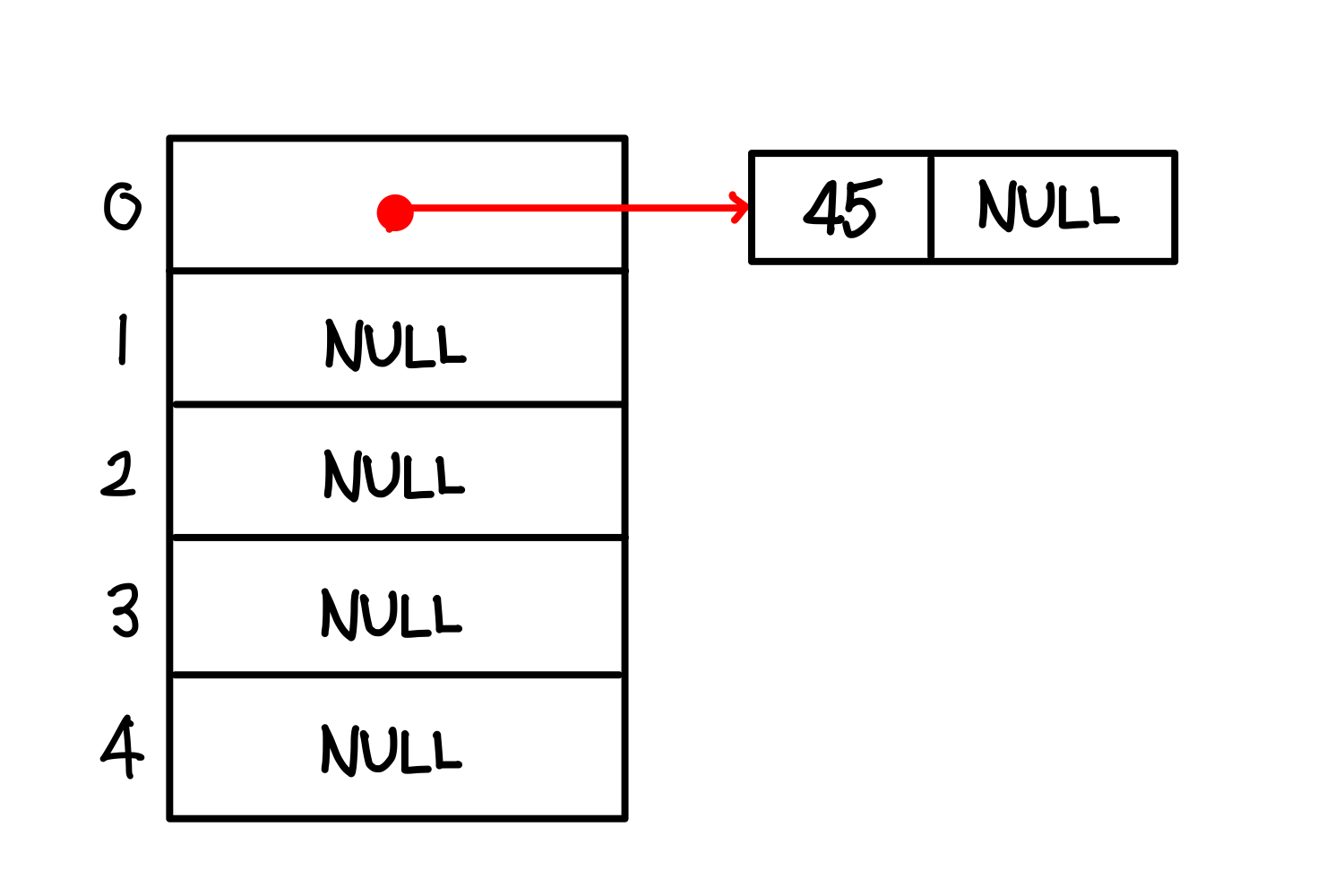
2. h(9) = 9 mod 5 = 4 -> 해시 테이블 4번에 노드를 삽입하고 키값 9를 저장
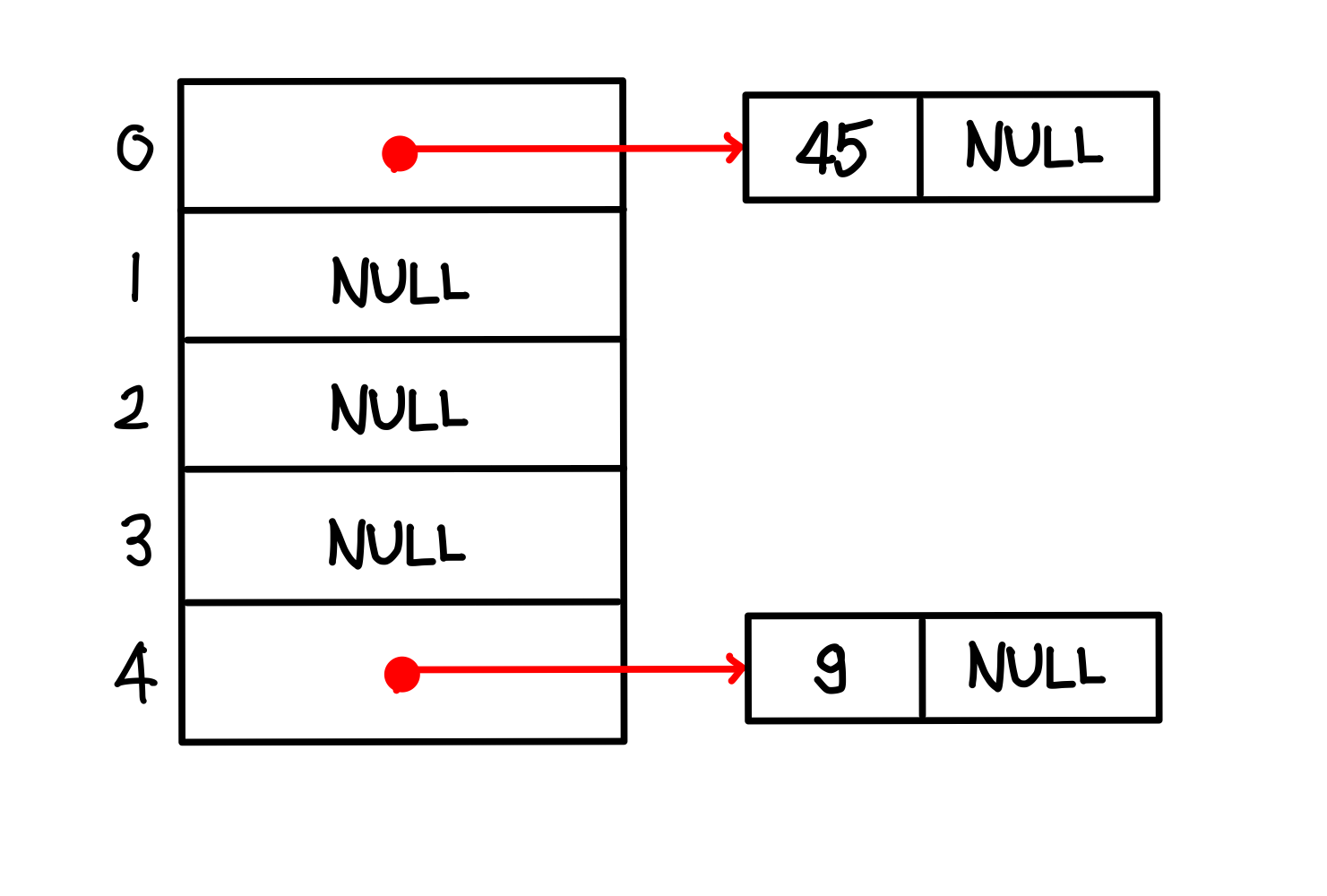
3. h(10) = 10 mod 5 = 0 -> 해시 테이블 0번에 노드를 삽입하고 키값 10을 저장
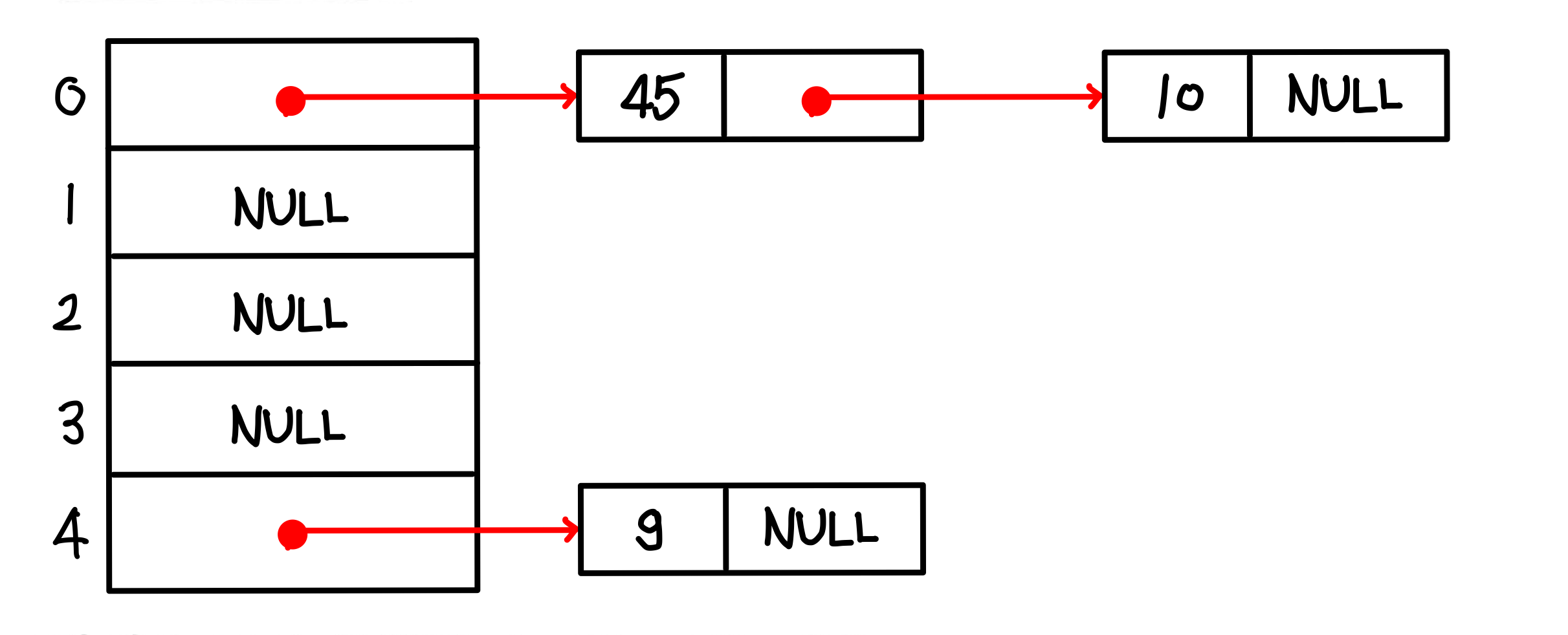
4. h(96) = 96 mod 5 = 1 -> 해시 테이블 1번에 노드를 삽입하고 키값 96을 저장
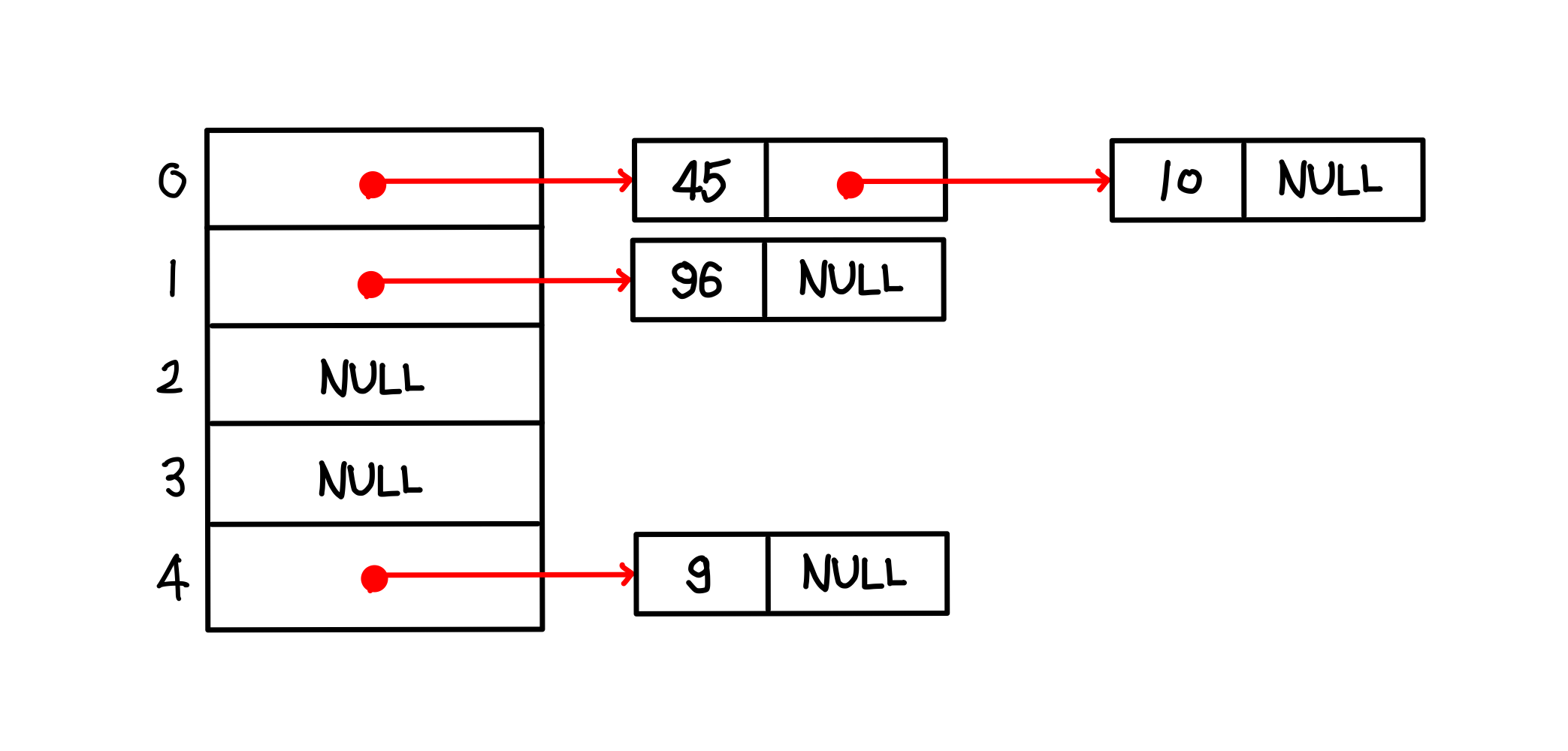
이렇게 해싱에 대해서 알아보았다 그러면 코드도 작성해해 보아야겠다.
해싱 체이닝을 이용한 단어 사전 프로그램을 만들어 보았다.
간단한 단어 사전 프로그램
/*
* 작성자: 권순욱
* 작성일: 2023-12-07
* 최종 수정일: 2023-12-08
* 설명: 이 코드는 해시 테이블(체이닝)을 사용한 간단한 사전 프로그램입니다.
*
* 주요 기능:
* 1. 단어와 해당하는 의미를 저장하고 검색할 수 있습니다.
* 2. 각 단어는 해시 함수를 통해 계산된 인덱스에 저장되며, 충돌은 체이닝을 통해 처리됩니다.
* 3. 메뉴를 통해 출력, 입력, 삭제, 검색 등의 동작을 수행할 수 있습니다.
*
* 자료 구조:
* - element: 영어 사전 항목을 나타내는 구조체로 단어와 의미를 저장합니다.
* - Node: 해시 테이블의 각 노드를 나타내는 구조체로 element 데이터와 다음 노드를 가리키는 포인터를 포함합니다.
* - Bucket: 해시 테이블의 버켓을 나타내는 구조체로 맨 앞 노드와 노드의 개수를 저장합니다.
*
* 함수:
* - hashFunction: 문자열을 기반으로 한 해시 함수로, 해시 키를 계산합니다.
* - createNode: 새로운 노드를 생성하는 함수로, 메모리를 할당하고 데이터를 초기화합니다.
* - addKey: 새로운 키를 해시 테이블에 추가하는 함수입니다.
* - removeKey: 주어진 키를 해시 테이블에서 삭제하는 함수입니다.
* - searchKey: 주어진 키를 해시 테이블에서 검색하여 의미를 출력하는 함수입니다.
* - display: 해시 테이블 전체를 출력하는 함수입니다.
* - menu: 사용자에게 메뉴를 출력하는 함수입니다.
* - main: 프로그램의 진입점으로, 사용자 입력을 받아 각 기능을 수행합니다.
*
* 예시 데이터:
* - 프로그램 실행 시 예시 데이터가 해시 테이블에 추가되어 있습니다.
* - 추가된 예시 데이터: "apple", "학교", "banana", "도서관", "orange", "국립공원", "grape", "컴퓨터", "strawberry", "초등학교"
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_WORD_LENGTH 20
#define MAX_MEAN_LENGTH 200
#define BUCKET_SIZE 10
// 영어 사전 항목의 구조 정의
typedef struct element {
char word[MAX_WORD_LENGTH];
char mean[MAX_MEAN_LENGTH];
} element;
// 영어 사전 노드 구조 정의
typedef struct Node {
element data;
int key; // 해시 키
struct Node* next; // 연결 리스트의 다음 노드를 가리키는 포인터
} Node;
// 버켓 구조체 선언
typedef struct bucket {
struct Node* head; // 각 버켓의 맨 앞 노드를 가리키는 포인터
int count; // 버켓에 저장된 노드의 수
} Bucket;
// 해쉬함수 만들기. 여기서는 Unicode 문자를 기반으로 해시를 계산
int hashFunction(const char* key) {
unsigned int sum = 0;
int length = strlen(key);
for (int i = 0; i < length; ++i) {
sum = (sum * 31) + key[i];
}
return sum % BUCKET_SIZE;
}
// 새로운 노드를 생성하는 함수
Node* createNode(int key, element* data) {
// 메모리 할당
Node* newNode = (Node *)malloc(sizeof(Node));
// 메모리 할당 실패 시 NULL 반환
if (newNode == NULL) {
return NULL;
}
// 노드의 정보 설정
(*newNode).key = key;
// strncpy을 사용하여 문자열을 복사하고 널 종료 문자를 추가
strncpy((*newNode).data.word, (*data).word, MAX_WORD_LENGTH - 1);
(*newNode).data.word[MAX_WORD_LENGTH - 1] = '\0';
strncpy((*newNode).data.mean, (*data).mean, MAX_MEAN_LENGTH - 1);
(*newNode).data.mean[MAX_MEAN_LENGTH - 1] = '\0';
(*newNode).next = NULL; // 생성할 때는 next를 NULL로 초기화
return newNode;
}
// 새로운 키를 추가하는 함수
void addKey(const char* key, element* data, Bucket* hash_Table) {
// 해쉬를 계산하는 함수로부터 버켓의 인덱스 번호를 구함.
int hash_Index = hashFunction(key);
// 새로운 노드 생성
Node* newNode = createNode(hash_Index, data);
// 계산된 버켓의 인덱스에 아무것도 없을 때.
if (hash_Table[hash_Index].count == 0) {
hash_Table[hash_Index].count = 1;
hash_Table[hash_Index].head = newNode;
} else { // 계산된 버켓이 이미 노드가 존재할 때... 기존의 노드를 한칸 씩 이동.
// 즉 새로 추가되는 모든 키는 헤드가 된다.
(*newNode).next = hash_Table[hash_Index].head;
hash_Table[hash_Index].head = newNode;
hash_Table[hash_Index].count++;
}
}
// 키(노드)를 삭제하는 함수
void removeKey(const char* key, Bucket* hash_Table) {
// 해시를 계산하여 버켓의 인덱스 번호를 구함
int hash_Index = hashFunction(key), flag = 0;
// 노드를 순회하는데 현재 노드와 이전 노드의 주소를 담을 노드들.
Node* temp, * before_temp;
// 각 버켓의 맨 앞 노드부터 순회 시작.
temp = hash_Table[hash_Index].head;
while (temp != NULL) { // 마지막 노드는 항상 NULL이기에...
if (strcmp((*temp).data.word, key) == 0) {
// 노드가 헤드인 경우 다음 노드를 헤드로 변경하고, 헤드가 아닌 경우 전 노드가 현재의 다음 노드를 가리킴.
(temp == hash_Table[hash_Index].head) ? (hash_Table[hash_Index].head = (*temp).next) : ((*before_temp).next = (*temp).next);
// 키를 삭제를 하였기에 갯수 차감.
hash_Table[hash_Index].count--;
// 삭제할 노드 할당 취소
free(temp);
flag = 1;
break;
}
before_temp = temp;
temp = (*temp).next;
}
// flag의 값에 따라 출력 다르게 해줌
(flag == 1) ? printf("\n [ %s ] 이/가 삭제되었습니다. \n", key) : printf("\n [ %s ] 이/가 존재하지 않아 삭제하지 못했습니다.\n", key);
}
/*
검색하는 함수에서 제대로 검색이 되지 않는 문제 발생.
원인을 찾아보니 검색하는 함수에서는 입력을 받을 때 개행 문자 '\n'을 같이 받아와 검색하지만 실제로
해시 테이블에 저장된 문자열에는 개행 문자를 지우고 저장했기에 이런 일이 발생. 해결완료~
*/
void searchKey(const char* key, Bucket* hash_Table) {
// 사용자 입력에서 개행 문자를 제거한 단어를 저장할 변수
char cleanKey[MAX_WORD_LENGTH];
strncpy(cleanKey, key, MAX_WORD_LENGTH - 1);
cleanKey[MAX_WORD_LENGTH - 1] = '\0';
// 입력된 키에서 개행 문자를 제거합니다.
cleanKey[strcspn(cleanKey, "\n")] = '\0';
// 해시를 계산하여 버켓의 인덱스 번호를 구합니다.
int hash_Index = hashFunction(cleanKey);
// 노드를 순회하는데 사용할 반복자 선언
Node* iterator = hash_Table[hash_Index].head;
// 버켓이 비어있는 경우
if (hash_Table[hash_Index].count == 0) {
printf("\n [ %s ] 은/는 사전에 존재하지 않습니다.\n", cleanKey);
return;
}
// 노드를 순회하며 키를 찾음
while (iterator != NULL) {
if (strcmp((*iterator).data.word, cleanKey) == 0) {
printf("\n [ %s ] 의 뜻은 [ %s ] 입니다.\n", cleanKey, (*iterator).data.mean);
return;
}
iterator = (*iterator).next;
}
// 키를 찾지 못한 경우
printf("\n [ %s ] 은/는 사전에 존재하지 않습니다.\n", cleanKey);
}
// 헤시테이블을 출력하는 함수
void display(Bucket* hash_Table) {
// 반복자 선언
Node* iterator;
printf("\n========= [사전 출력] ========= \n");
for (int i = 0; i < BUCKET_SIZE; i++) {
iterator = hash_Table[i].head;
printf("Bucket[%d] : ", i);
while (iterator != NULL) {
printf("(key : %d, 단어 : %s, 의미 : %s) -> ", (*iterator).key, (*iterator).data.word, (*iterator).data.mean);
iterator = (*iterator).next;
}
printf("\n");
}
printf("\n========= [사전 끝] ========= \n");
}
// 메뉴 출력 함수
void menu(element* data) {
printf("\n*---------------------------*");
printf("\n\t1 : 출력");
printf("\n\t2 : 입력");
printf("\n\t3 : 삭제");
printf("\n\t4 : 검색");
printf("\n\t5 : 종료");
printf("\n*---------------------------*\n ");
}
// 프로그램 진입점
int main(void) {
int choice;
// 사용자 입력을 받을 데이터 구조체
element* data = (element*)malloc(sizeof(element));
// 해시테이블 메모리 할당
Bucket* hash_Table = (Bucket*)malloc(BUCKET_SIZE * sizeof(struct bucket));
// 해시테이블 초기화
for (int i = 0; i < BUCKET_SIZE; i++) {
hash_Table[i].head = NULL;
hash_Table[i].count = 0;
}
// 예시 데이터 추가
addKey("apple", &(element){"apple", "red fruit"}, hash_Table);
addKey("학교", &(element){"학교", "교육 기관"}, hash_Table);
addKey("banana", &(element){"banana", "yellow fruit"}, hash_Table);
addKey("도서관", &(element){"도서관", "책 저장소"}, hash_Table);
addKey("orange", &(element){"orange", "orange fruit"}, hash_Table);
addKey("국립공원", &(element){"국립공원", "자연 보호 구역"}, hash_Table);
addKey("grape", &(element){"grape", "purple fruit"}, hash_Table);
addKey("컴퓨터", &(element){"컴퓨터", "정보 처리 장치"}, hash_Table);
addKey("strawberry", &(element){"strawberry", "red fruit"}, hash_Table);
addKey("초등학교", &(element){"초등학교", "초등 교육 기관"}, hash_Table);
do {
menu(data);
printf("메뉴를 선택하세요 : ");
scanf("%d", &choice);
getchar(); // 개행 문자를 소진하기 위해 추가
switch (choice) {
case 1:
display(hash_Table);
break;
case 2:
printf("\n[단어 입력] 단어를 입력하시오 : ");
fgets((*data).word, MAX_WORD_LENGTH, stdin);
(*data).word[strcspn((*data).word, "\n")] = '\0'; // 개행 문자 제거
printf("\n[단어입력] 단어의 뜻을 입력하시오 : ");
fgets((*data).mean, MAX_MEAN_LENGTH, stdin);
(*data).mean[strcspn((*data).mean, "\n")] = '\0'; // 개행 문자 제거
addKey((*data).word, data, hash_Table);
break;
case 3:
printf("\n[단어 삭제] 삭제할 단어 : ");
fgets((*data).word, MAX_WORD_LENGTH, stdin);
(*data).word[strcspn((*data).word, "\n")] = '\0'; // 개행 문자 제거
removeKey((*data).word, hash_Table);
break;
case 4:
printf("\n[단어 검색] 검색할 단어 : ");
fgets((*data).word, MAX_WORD_LENGTH, stdin);
searchKey((*data).word, hash_Table);
break;
case 5: break;
default:
printf("\n없는 메뉴입니다. 다시 선택해주세요!\n");
}
} while (choice != 5);
// 동적으로 할당된 메모리 해제
free(data);
// 각 버킷의 노드들을 해제
for (int i = 0; i < BUCKET_SIZE; i++) {
Node* temp = hash_Table[i].head;
while (temp != NULL) {
Node* next = (*temp).next;
free(temp);
temp = next;
}
}
// 해시테이블 메모리 해제
free(hash_Table);
// 프로그램 종료 전에 사용자가 결과를 확인할 수 있도록 대기
puts("종료하실려면 아무키나 누루세요.");
getchar();
return 0;
}
---------------------------------------------------------------------------------
*---------------------------*
1 : 출력
2 : 입력
3 : 삭제
4 : 검색
5 : 종료
*---------------------------*
메뉴를 선택하세요 : 1
========= [사전 출력] =========
Bucket[0] : (key : 0, 단어 : apple, 의미 : red fruit) ->
Bucket[1] : (key : 1, 단어 : 초등학교, 의미 : 초등 교육 기관) ->
Bucket[2] : (key : 2, 단어 : 도서관, 의미 : 책 저장소) ->
Bucket[3] : (key : 3, 단어 : strawberry, 의미 : red fruit) ->
Bucket[4] :
Bucket[5] :
Bucket[6] : (key : 6, 단어 : 컴퓨터, 의미 : 정보 처리 장치) -> (key : 6, 단어 : orange, 의미 : orange fruit) ->
Bucket[7] : (key : 7, 단어 : grape, 의미 : purple fruit) ->
Bucket[8] : (key : 8, 단어 : 학교, 의미 : 교육 기관) ->
Bucket[9] : (key : 9, 단어 : 국립공원, 의미 : 자연 보호 구역) -> (key : 9, 단어 : banana, 의미 : yellow fruit) ->
========= [사전 끝] =========
*---------------------------*
1 : 출력
2 : 입력
3 : 삭제
4 : 검색
5 : 종료
*---------------------------*
메뉴를 선택하세요 : 3
[단어 삭제] 삭제할 단어 : 컴퓨터
[ 컴퓨터 ] 이/가 삭제되었습니다.
*---------------------------*
1 : 출력
2 : 입력
3 : 삭제
4 : 검색
5 : 종료
*---------------------------*
메뉴를 선택하세요 : 2
[단어 입력] 단어를 입력하시오 : 컴퓨터
[단어입력] 단어의 뜻을 입력하시오 : 정보 처리 장치
*---------------------------*
1 : 출력
2 : 입력
3 : 삭제
4 : 검색
5 : 종료
*---------------------------*
메뉴를 선택하세요 : 1
========= [사전 출력] =========
Bucket[0] : (key : 0, 단어 : apple, 의미 : red fruit) ->
Bucket[1] : (key : 1, 단어 : 초등학교, 의미 : 초등 교육 기관) ->
Bucket[2] : (key : 2, 단어 : 도서관, 의미 : 책 저장소) ->
Bucket[3] : (key : 3, 단어 : strawberry, 의미 : red fruit) ->
Bucket[4] :
Bucket[5] :
Bucket[6] : (key : 6, 단어 : 컴퓨터, 의미 : 정보 처리 장치) -> (key : 6, 단어 : orange, 의미 : orange fruit) ->
Bucket[7] : (key : 7, 단어 : grape, 의미 : purple fruit) ->
Bucket[8] : (key : 8, 단어 : 학교, 의미 : 교육 기관) ->
Bucket[9] : (key : 9, 단어 : 국립공원, 의미 : 자연 보호 구역) -> (key : 9, 단어 : banana, 의미 : yellow fruit) ->
========= [사전 끝] ========='알고리즘' 카테고리의 다른 글
| [알고리즘] 검색 1 -순차 검색, 이진 검색, 트리 검색 (0) | 2023.12.09 |
|---|---|
| [알고리즘] 정렬 6 - 히프 정렬 Heap Srot, 트리 정렬 Tree Sort (0) | 2023.12.09 |
| [알고리즘] 정렬 5 - 기수 정렬 Radix Sort (0) | 2023.12.09 |
| [알고리즘] 정렬 4 - 병합 정렬(2-way, n-way) (0) | 2023.12.09 |
| [알고리즘] 정렬 3 - 삽입정렬, 셸 정렬 (0) | 2023.12.09 |