목차
머신러닝
동물을 인식하는 SW를 만들어본다고 가정해보자.
함수나 모듈을 생성하고 해당 함수로 이미지를 입력 받아, 이미지가 고양이에 속하는지 강아지에 속하는지 정답을 반환하는 프로그램이 필요하다. 하지만 고양이나 강아지의 사진은 조명, 각도, 고양이나 강아지의 자세에 따라서 너무 다르기 때문에 사진으로부터 공통된 명확한 특징을 잡아내는 것이 쉽지 않다. 더불어 프로그램으로 수천 개의 연산을 하는 것과 같은 알고리즘을 만드는 것은 매우 쉽지 않다.
그에 반면, 머신러닝은 데이터로부터 결과를 찾는 것이 아니라 주어진 데이터로부터 규칙성을 찾는 것이 목표이다.
여기서 데이터로부터 규칙성을 찾는 과정을 학습이라고 한다.
일단 규칙성을 발견하면(여기서 규칙성이란 머신러닝 모델을 말한다.) 이후에 들어오는 새로운 데이터에 대해서 발견한 규칙성을 기준으로 정답을 찾아내는데, 이는 위에 말한 프로그래밍 방식으로 접근하기 어려웠던 문제에 대한 해결책이다.
| 문제 발생 | 사람 | 기존 프로그램 | 머신러닝 |
| 매우 많은 양의 숫자를 빠르게 곱하기 | 어려움 | 쉬움 | 쉬움 |
| 사진에서 사람들의 얼굴 찾기 | 쉬움 | 어려움 | 쉬움 |
머신러닝의 시작은 정의하기 어렵다. 가장 일반적인 주장은 1949년에 햅(Hebb)이 학습 이론(Hebbian Learning Theory)을 발표하는 것으로 시작되어 이후 1952년 IBM에서 근무하던 아서 새뮤얼은 최초의 머신러닝 프로그램이라 할 수 있는 체커 프로그램을 개발하였다.
이때 경험으로부터 배우는 방법 이론을 주장하였고, 여기서 머신러닝이란 '명확히 프로그램하지 않고도 컴퓨터가 사고하는 기능'이라고 정의가 되었다.
머신러닝 구성
많은 머신러닝 문제는 1개 이상의 독립변수 X를 가지고 종속변수 Y를 예측하는 문제들이다. 특히 딥러닝과 같은 인공신경망 모델은 독립변수, 종속변수, 가중치, 편항 등을 행렬을 통해 연산하는 경우가 많다. 따라서 딥러닝을 배우게 된다면 훈련 데이터를 행렬로 표현하는 경우를 많이 보는데 판다스에서 사용하는 데이터프레임 구조를 행렬로 이해하면 된다.
그리고 머신러닝에서는 하나의 데이터, 하나의 행을 샘플(Sample)이라 부르고 종속변수룰 예측하기 위한 각각의 독립 변수를 특징(Feature)라고 한다.
| 독립, 입력, 설명변수 | 출력변수, 목표변수, 종속변수, 라벨, 레이블, 클래스 ↓ |
|||||
| 번호 | 성별 | 나이 | 거주지 | 소득 | 여부 | |
| 샘플(행) -> | 1 | F | 21 | H | 333 | Y |
| 샘플(행) -> | 2 | M | 33 | H | 355 | Y |
| 샘플(행) -> | 3 | F | 55 | D | 555 | N |
| 샘플(행) -> | 4 | F | 53 | D | 454 | N |
머신러닝 문제
머린러닝 문제들은 대부분 분류와 회귀에 속한다. 분류는 위의 표와 같이 범주형 레이블을 예측하는 것이다. 예를 들어 예(Y)/아니오(N) 등과 같은 형태를 말한다. 반면 회귀는 연속된 값을 예측하는 것이다.
정리하자면 분류는 범주형을 예측하는 것이고, 회귀는 연속형을 예측한다고 생각하면 된다.
1) 분류 : 범주형 레이블 예측
분류(Classification)는 단어 뜻 그대로 클래스(라벨, 종속변수)를 구분하여 예측하는 것이다. 예측해야 할 대상 즉, 클래스가 정해져있다.
많은 사례로 딥러닝 교재에서 언급되는 강아지, 고양이 이미지 예측 문제 같은 것들이다.
앞서 설명했던 선형회귀를 통해 과학으로 수학 점수를 예측한 것은 연속형 예측이기에 회귀 예측에 속하고, 로지스틱 회귀는 이름은 회귀이지만 분류 문제를 예측한 것이었다.
⓵ 이진 분류
이진 분류(Binary Classification)는 주어진 독립변수에 대해서 종속변수 둘 중 하나의 답을 구분하는 문제이다.
앞에서 해보았던 시험 성적에 대해서 합격과 불합격 여부를 판단하는 문제도 여기에 속하며 내가 받은 메일이 스팸인지 아닌지 판단하는 문제도 이진 분류에 속한다.
⓶ 다중 클래스 분류
다중 클래스 분류(Multi-class Classification)는 입력 변수에 대한 두 개 이상의 정해진 선택지 중에서 답을 분류하는 문제이다.
머신러닝을 사례로 많이 소개된 붓꽃의 품종을 예측하는 것은 3개의 클래스를 가지고 있기 때문에 다중 분류에 속한다.
3개의 선택지를 주로 카테고리 또는 범주 또는 클래스라고 하며, 주어진 입력으로부터 정해진 클래스 중 하나로 판단하는 것을 다중 클래스 분류라고 한다.

2) 회귀 : 연속된 값을 예측
회귀(Regression)는 분류 문제처럼 1 또는 0이나 붓꽃의 클래스와 같이 분리된(비연속적인) 답을 예측하는 것이 아니라 연속된 값을 예측한다. 회귀는 연속적인 숫자(실수)를 예측하는 것이다.
사람의 교육 수준과 나이 등을 이용해 연봉을 예측하는 것을 회귀 문제의 예라고 하는데 더 많다.
|
그리고 종속 변수에 연속성이 있다면 회귀 문제라고 볼 수 있는데, 연봉을 예상할 때 얼마든 큰 문제가 되지 않는다. 하지만 분류 문제에서는 중간은 없다. 예를 들어 스팸 메일을 분류하면 스팸 메일이거나 아니거나 두 가질 나누어지는 것이지 그 사이에 속한 메일은 없다.
머신러닝 학습 구분
머신러닝 과정은 데이터를 사용해 모델을 생성하고 학습을 반복하는 과정이다. 머신러닝에서 학습은 지도 학습, 비지도 학습, 강화 학습으로 구분한다.
| 머신러닝 | ||
| ↓ | ↓ | ↓ |
| 지도 학습 | 비지도 학습 | 강화 학습 |
지도 학습 (Supervised Learning)
비유: 학교에서 선생님이 알려주는 공부 방법
- 설명: 선생님이 문제와 답을 알려주면서 공부하는 것처럼, 컴퓨터에게도 입력과 그에 맞는 정답을 알려줘서 학습시킨다. 예를 들어, 여러 가지 동물 사진(입력)과 그 동물의 이름(정답)을 컴퓨터에게 보여준다. 그러면 컴퓨터는 다음에 새로운 동물 사진을 보았을 때 그 동물의 이름을 맞출 수 있게 된다.
- 예시:
- 강아지 사진을 보고 "강아지"라고 맞추기.
- 숫자 문제를 풀어서 답을 맞추기.
- 문제지와 정답지:
- 선생님이 문제지와 정답지를 주고, "이 문제의 답은 이거야!"라고 가르쳐준다.
- 컴퓨터에게 "이 사진은 강아지야", "이 사진은 고양이야"라고 가르쳐주면, 컴퓨터는 다음에 새로운 사진을 보았을 때 강아지인지 고양이인지 맞출 수 있다.
비지도 학습 (Unsupervised Learning)
비유: 혼자서 놀이터에서 노는 방법을 배우기
- 설명: 놀이터에서 놀 때, 선생님이나 부모님이 직접 가르쳐주지 않아도 스스로 놀이터의 놀이기구를 사용하면서 어떻게 노는지 배우는 것처럼, 컴퓨터에게도 입력 데이터만 주고 스스로 데이터를 분석하고 패턴을 찾게 한다. 예를 들어, 여러 가지 과일 사진을 보여주면, 컴퓨터는 비슷하게 생긴 과일들끼리 그룹을 나눌 수 있다.
- 예시:
- 같은 종류의 과일 사진을 묶기.
- 다양한 색상의 공을 색깔별로 나누기.
- 퍼즐맞추기:
- 퍼즐을 맞출 때, 처음에는 아무런 도움 없이 퍼즐 조각들을 보고 어떻게 맞춰야 하는지 스스로 생각해본다.
- 컴퓨터에게 여러 가지 사진을 보여주면, 컴퓨터는 비슷하게 생긴 사진들을 그룹으로 묶는다. 예를 들어, 사과 사진과 오렌지 사진을 따로 그룹으로 묶을 수 있다.
강화 학습 (Reinforcement Learning)
비유: 게임에서 보상을 받으면서 배우기
- 설명: 아이가 게임을 하면서 특정 행동을 했을 때 점수를 얻거나 잃는 경험을 통해 더 좋은 방법을 배우는 것처럼, 컴퓨터도 어떤 행동을 했을 때 얻는 보상이나 벌점을 통해 최적의 행동을 학습한다. 예를 들어, 미로를 빠져나가는 게임에서 올바른 길로 가면 보상을 주고, 잘못된 길로 가면 벌점을 준다. 컴퓨터는 최종적으로 보상을 최대화하는 방법을 배우게 된다.
- 예시:
- 게임 캐릭터가 미로를 빠져나가도록 학습하기.
- 로봇이 장애물을 피하면서 목적지에 도달하게 하기.
- 게임 레벨 업:
- 게임에서 캐릭터가 점프해서 코인을 먹으면 점수가 올라가고, 장애물에 부딪히면 점수가 내려간다. 아이는 점수를 많이 얻기 위해 더 잘 점프하고 장애물을 피하는 방법을 배운다.
- 컴퓨터에게도 이런 식으로 보상과 벌점을 주면, 컴퓨터는 더 좋은 점수를 얻기 위해 최적의 방법을 배우게 된다.
| 항목 | 지도 학습(Supervised Learning) | 비지도 학습(Unsupervised Learning) |
| 목적 | 주어진 입력에 대한 정확한 출력을 예측하는 모델을 만드는 것 | 데이터 내에서 숨겨진 패턴이나 그룹을 발견하는 것 |
| 장점 | 높은 정확도, 결과 해석에 용이하다. | 레이블이 없는 데이터에서도 패턴을 찾을 수 있다. |
| 단점 | 많은 레이블된 데이터가 필요하며 레이블링 비용이 많이듬 | 결과 해석이 어려울 수 있고 특정 문제에 대한 최적의 솔루션이 아니다.(분석가의 판단에 의지) |
| 검증 방법 | 훈련 데이터와 테스트 데이터로 나누어 교차 검증 | 군집의 내적 일관성, 실루엣 계수, 엘보 방법 등을 사용한 평가(별도의 검증 필요 없음) |
| 데이터 | 레이블이 있는 데이터 (입력과 출력이 쌍으로 이루어진 데이터) | 레이블이 없는 데이터 (입력만 존재) |
| 유형 | 분류(Classification): 그룹별 특징 파악 회귀(Regression) Y = X |
군집화(Clustering) : 데이터 클러스터링, 패턴 인식 : 여러 그룹 인식 차원 축소(Dimensionality Reduction) |
| 주요 알고리즘 |
로지스틱 회귀(Logistic Regression), 결정 트리(Decision Tree), 랜덤 포레스트(Random Forest), 서포트 벡터 머신(SVM) 등 | K-평균(K-means), 계층적 군집화(Hierarchical Clustering), 주성분 분석(PCA) 등 |
| 사례 | 이메일 스팸 필터링, 이미지 분류, 주택 가격 예측 등 | 고객 세분화, 상품 추천, 이상치 탐지 등 |
머신러닝 평가
1) 데이터 분할
머신러닝 모델이 완성되었다면, 전체 데이터를 학습을 위한 훈련용 데이터와 평가를 위한 테스트용 데이터로 분할(Split)한다. 특별한 경우에는 훈련용, 검증용, 테스트용 데이터로 세 가지로 분리하기도 한다.
1-1. 훈련 데이터 (Training Data)
- 설명: 머신러닝 모델을 학습하는 데 사용하는 데이터이다. 모델이 열심히 공부하는 과정에서 사용하는 데이터라고 생각하면 된다.
- 비유: 학생이 시험을 준비하기 위해 푸는 연습 문제지와 같다.
1-2. 테스트 데이터 (Testing Data)
- 설명: 학습이 완료된 모델의 성능을 평가하는 데 사용하는 데이터이다. 모델이 실제로 얼마나 잘 예측하는지 확인하기 위해 사용한다.
- 비유: 학생이 공부한 후에 치르는 실제 시험과 같다.
1-3. 검증 데이터 (Validation Data) (선택사항)
- 설명: 모델의 하이퍼파라미터를 조정하고 최적화하는 데 사용하는 데이터이다. 학습 과정 중에 모델의 성능을 평가하고 조정하기 위해 사용한다.
- 비유: 학생이 중간에 실력을 점검하기 위해 보는 모의고사와 같다.
2) 모델 학습 (Model Training)
훈련 데이터를 사용하여 머신러닝 모델을 학습시킨다.
- 설명: 모델이 훈련 데이터를 통해 패턴을 배우고 입력과 출력 간의 관계를 이해하게 된다.
- 비유: 학생이 연습 문제지를 풀면서 공부하는 과정과 같다.
3) 모델 평가 (Model Evaluation)
모델 평가는 우수한 머신러닝 모델을 결정하는 단계로, 모델이 얼마나 정확하게 예측한 결과와 실제 정답이 일치하는지를 검증하는 과정이다. 다양한 평가 지표를 통해 모델의 성능을 측정하고, 이를 기반으로 모델을 개선할 수 있다. 주요 평가 지표에는 혼동 행렬(Confusion Matrix), 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), 그리고 ROC 곡선(Receiver Operating Characteristic Curve)이 있다.
- 설명: 학습이 완료된 모델이 새로운 데이터(테스트 데이터)를 얼마나 정확하게 예측하는지 평가한다.
- 비유: 학생이 시험을 치르고 성적을 확인하는 과정과 같다.
혼동 행렬 (Confusion Matrix)
혼동 행렬은 분류 문제에서 모델의 성능을 나타내는 표로, 예측 결과와 실제 값을 비교하여 TP, FP, FN, TN의 값을 계산한다.
- True Positive (TP): 실제로 참인 정답을 모델이 참이라고 예측한 경우.
- False Positive (FP): 실제로 거짓인 정답을 모델이 참이라고 예측한 경우.
- False Negative (FN): 실제로 참인 정답을 모델이 거짓이라고 예측한 경우.
- True Negative (TN): 실제로 거짓인 정답을 모델이 거짓이라고 예측한 경우.
| 예측 : 참(Positive) | 예측 : 거짓(Negative) | |
| 실제 : 참 | TP | FP |
| 실제 : 거짓 | FN | TN |
주요 평가 지표
1. 정확도 (Accuracy)
정확도는 모델이 올바르게 예측한 비율을 나타낸다. 즉, 전체 예측 중에서 맞춘 비율을 계산한다.
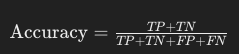
예시: 100개의 데이터 중 90개를 맞추면, 정확도는 90%이다.
2. 정밀도 (Precision)
정밀도는 모델이 참이라고 예측한 것 중에서 실제로 참인 비율을 나타낸다.
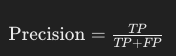
설명: 모델이 참이라고 예측한 것 중에서 실제로 맞춘 비율을 나타낸다.
예시: 모델이 10개를 참이라고 예측했는데 그 중 8개가 실제로 참이라면, 정밀도는 80%이다.
3. 재현율 (Recall)
재현율은 실제로 참인 것 중에서 모델이 참이라고 예측한 비율을 나타낸다.
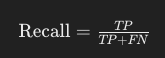
설명: 실제로 참인 것 중에서 모델이 맞춘 비율을 나타낸다.
예시: 실제로 참인 것이 10개인데, 모델이 그 중 7개를 맞췄다면, 재현율은 70%이다.
4. F1 점수 (F1 Score)
F1 점수는 정밀도와 재현율의 조화 평균을 나타낸다. 정밀도와 재현율 사이의 균형을 고려할 때 유용하다.
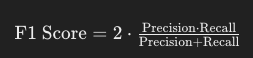
설명: 정밀도와 재현율의 균형을 고려한 성능 지표.
예시: 정밀도와 재현율이 모두 80%일 때, F1 점수도 80%가 된다.
5. ROC 곡선과 AUC (Receiver Operating Characteristic Curve and Area Under Curve)
ROC 곡선은 다양한 임곗값에서의 분류 성능을 시각화한 그래프이다. AUC는 ROC 곡선 아래의 면적으로, 모델의 전체 성능을 평가하는 지표이다.
설명: ROC 곡선은 참 양성 비율(TPR)과 거짓 양성 비율(FPR)을 시각화한 그래프이다. AUC는 ROC 곡선 아래의 면적을 나타낸다.
예시: AUC 값이 1에 가까울수록 모델의 성능이 우수함을 나타낸다.
4) 모델 검증 (Model Validation) (선택사항)
검증 데이터를 사용하여 모델의 성능을 중간에 점검하고 최적화한다.
- 설명: 학습 과정 중에 모델의 성능을 평가하고, 하이퍼파라미터를 조정하여 최적의 성능을 찾는다.
- 비유: 학생이 모의고사를 보면서 중간에 실력을 점검하고 부족한 부분을 보완하는 과정과 같다.
요약
- 데이터 분할
- 훈련 데이터: 모델이 공부하는 데 사용하는 연습 문제지.
- 테스트 데이터: 모델이 공부한 후에 치르는 실제 시험.
- 검증 데이터(선택사항): 모델의 성능을 중간에 점검하는 모의고사.
- 모델 학습
- 설명: 훈련 데이터를 통해 모델이 패턴을 배우는 과정.
- 모델 평가
- 설명: 테스트 데이터를 사용하여 모델의 성능을 평가하는 과정.
- 모델 검증(선택사항)
- 설명: 검증 데이터를 사용하여 중간에 모델의 성능을 점검하고 최적화하는 과정.
머신러닝 준비
머신러닝이 거의 모든 분야의 주요 기술이 되어가고 있는 현재 많은 머신러닝 개발 프레림워크들이 생기거나 조명받기 시작했다.
그리고 각 프레임 워크의 선호들도 트랜드에 따라 계속 발전하고 있다.
1. TensorFlow
2. PyTorch
3. scikit-learn
4. Keras
5. XGBoost
|
1) 사이킷런
실무에서 가장 많이 사용하는 빅데이터 분석용 라이브러리는 판다스, 팻플롯립, 넘파이, 시본 등이다.
머신러닝에서는 사이킷런(Scikit-Learn)이 필요한 모듈을 대부분 가지고 있어서 많이 사용되며, 사이킷런은 지도/비지도 학습, 모델 선택 및 평가, 데이터 변환 및 데이터 불러오기, 계산 성능, 향상을 위한 기능 등 머신러닝에 필요한 대부분의 기능을 제공한다.
데이터 처리
데이터 처리는 머신러닝 프로젝트에서 매우 중요한 단계로, 데이터를 학습 가능한 형식으로 변환하는 과정을 포함합니다. scikit-learn의 preprocessing과 feature_extraction 모듈을 사용하여 데이터 전처리를 수행할 수 있습니다.
1. sklearn.preprocessing
- StandardScaler: 데이터를 표준화(평균 0, 표준편차 1)합니다.
- MinMaxScaler: 데이터를 정규화(최소값 0, 최대값 1)합니다.
- LabelEncoder: 범주형 데이터를 숫자로 변환합니다.
- OneHotEncoder: 범주형 데이터를 원-핫 인코딩합니다.
- Binarizer: 숫자 데이터를 이진 데이터로 변환합니다.
- PolynomialFeatures: 다항식 특징을 생성합니다.
from sklearn.preprocessing import StandardScaler, MinMaxScaler, LabelEncoder, OneHotEncoder, Binarizer, PolynomialFeatures
# 예시
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
encoder = OneHotEncoder()
X_encoded = encoder.fit_transform(X)2. sklearn.feature_extraction
- CountVectorizer: 텍스트 데이터를 단어 카운트 벡터로 변환합니다.
- TfidfVectorizer: 텍스트 데이터를 TF-IDF 벡터로 변환합니다.
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# 예시
vectorizer = CountVectorizer()
X_counts = vectorizer.fit_transform(text_data)
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(text_data)모델 선택 및 검증
모델 선택 및 검증 단계에서는 다양한 모델을 비교하고 최적의 모델을 선택합니다. scikit-learn의 model_selection 모듈을 사용하여 이 과정을 수행할 수 있습니다.
1. sklearn.model_selection
- train_test_split: 데이터를 훈련 세트와 테스트 세트로 분할합니다.
- cross_val_score: 교차 검증을 수행하여 모델 성능을 평가합니다.
- GridSearchCV: 하이퍼파라미터 튜닝을 위한 그리드 검색을 수행합니다.
- RandomizedSearchCV: 하이퍼파라미터 튜닝을 위한 랜덤 검색을 수행합니다.
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV, RandomizedSearchCV
# 예시
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
cross_val_scores = cross_val_score(model, X, y, cv=5)
param_grid = {'param1': [1, 10], 'param2': [0.1, 1]}
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)목표값 예측
목표값 예측 단계에서는 학습된 모델을 사용하여 새로운 데이터에 대해 예측을 수행합니다.
# 모델 학습
model.fit(X_train, y_train)
# 예측 수행
y_pred = model.predict(X_test)
# 회귀 문제에서는 목표값 예측
y_pred_regression = model.predict(X_test)
# 분류 문제에서는 목표값 예측
y_pred_classification = model.predict(X_test)
머신러닝 파이프라인
빅데이터 파이프라인은 앞서 이야기한 것을 바탕으로 정리하면 5단계로 구성된다.
빅데이터 파이프 라인이 완성되면 머신러닝 파이프라인으로 넘어가야한다.
| 빅데이터 | 데이터 전처리 | 머신러닝 |
| 1. 데이터 준비 | 1. 데이터 분할 | |
| 2. 데이터 보기 | 2. 모델링 | |
| 3. 데이터 클렌징 | 3. 모델 학습 | |
| 4. 데이터 탐색 | 4. 모델 평가 | |
| 5. 시각화 | 5. 배포 |
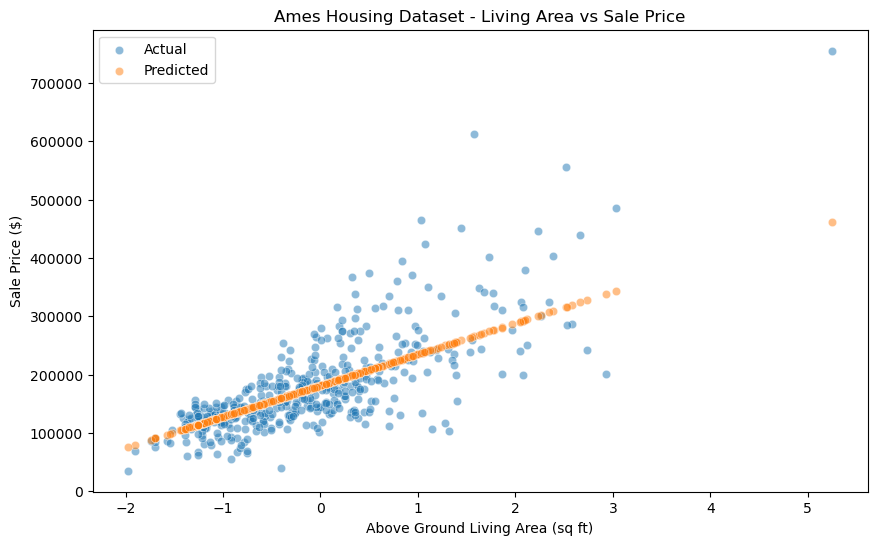
로지스틱 모델 예측(타이타닉)
import pandas as pd
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
import matplotlib.pyplot as plt
# 타이타닉 데이터 준비
df = pd.read_csv("titanic.csv")
# 1. 데이터 전처리 필요하지 않은 컬럼 삭제 (X변수)
del df['PassengerId'] # 승객 ID 컬럼 삭제
del df['Name'] # 이름 컬럼 삭제
del df['Ticket'] # 티켓 컬럼 삭제
del df['Cabin'] # 선실 정보 컬럼 삭제
# 결측치 처리 (X변수)
df.dropna(thresh=int(len(df) * 0.5), axis=1) # 결측치가 50% 이상인 컬럼 삭제
df['Embarked'] = df['Embarked'].fillna('S') # 'Embarked' 컬럼의 결측치를 최빈값 'S'로 대체
df['Age'] = df['Age'].fillna(df['Age'].mean()) # 'Age' 컬럼의 결측치를 평균값으로 대체
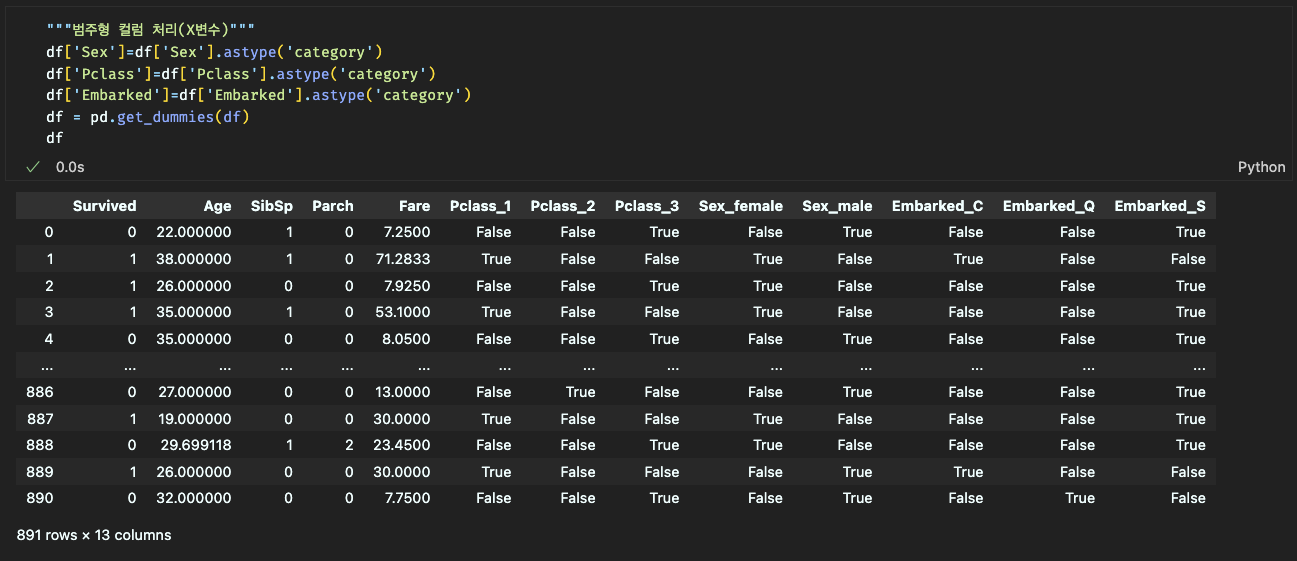
# 범주형 컬럼 처리 (X변수)
df['Sex'] = df['Sex'].astype('category') # 'Sex' 컬럼을 범주형 데이터로 변환
df['Pclass'] = df['Pclass'].astype('category') # 'Pclass' 컬럼을 범주형 데이터로 변환
df['Embarked'] = df['Embarked'].astype('category') # 'Embarked' 컬럼을 범주형 데이터로 변환
df = pd.get_dummies(df) # 원-핫 인코딩 수행
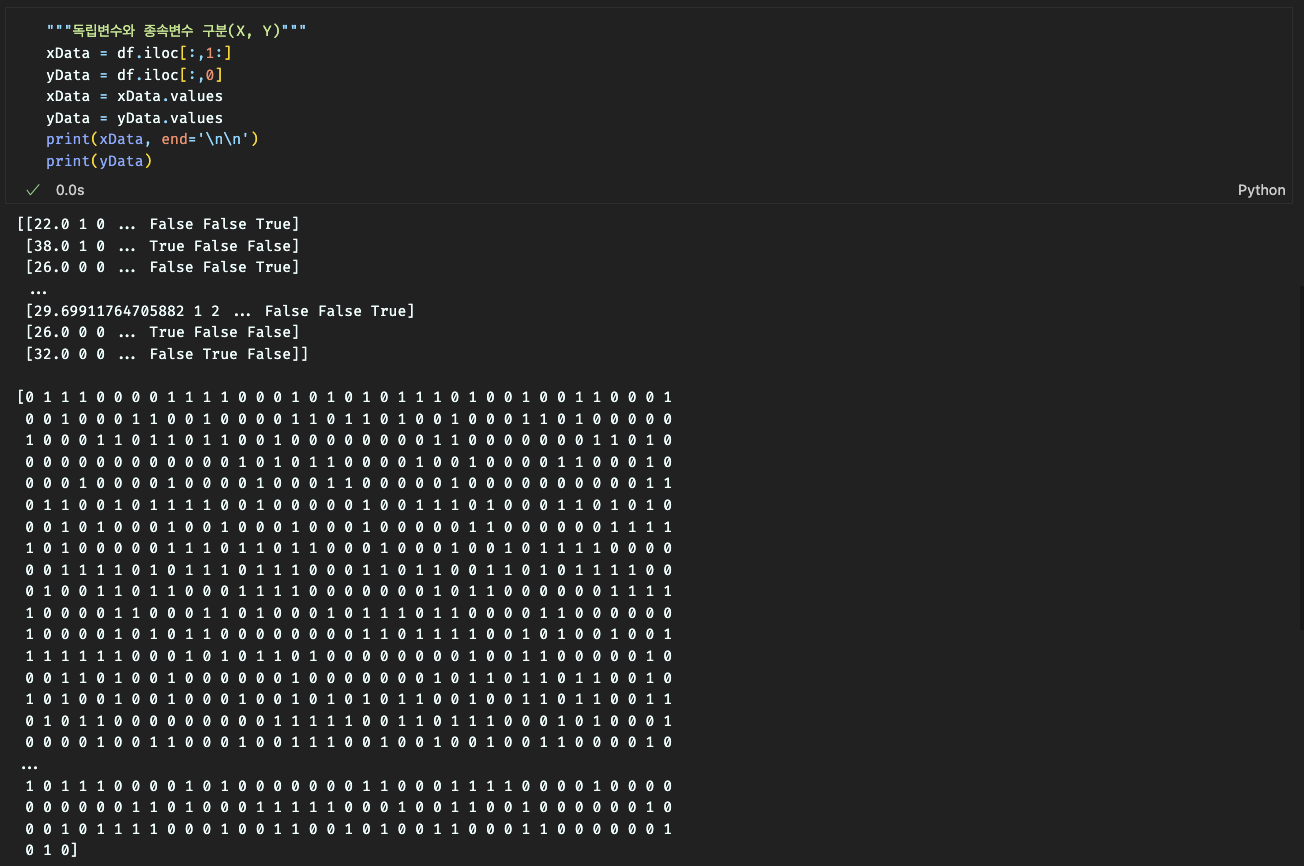
# 독립변수와 종속변수 구분 (X, Y)
x_Data = df.iloc[:, 1:] # 독립변수 (첫 번째 컬럼을 제외한 나머지)
y_Data = df.iloc[:, 0] # 종속변수 (첫 번째 컬럼)
x_Data = x_Data.values # DataFrame을 Numpy 배열로 변환
y_Data = y_Data.values # DataFrame을 Numpy 배열로 변환
# 머신러닝 파이프라인
# 데이터 분할 (7:3)
x_train, x_test, y_train, y_test = model_selection.train_test_split(
x_Data, # 독립변수 데이터
y_Data, # 종속변수 데이터
test_size=0.3, # 테스트 데이터 비율 (30%)
random_state=None # 데이터 분할 시 랜덤 시드 (None: 매번 다른 랜덤 분할)
) # 데이터 분할
# 로지스틱 모델링
estimator = LogisticRegression(
penalty='l2', # 정규화 유형 설정 (L2 정규화)
dual=False, # 이중(formulation) 여부 설정 (샘플 수보다 특성 수가 많을 때 유용)
tol=0.0001, # 수렴 기준 허용 오차 설정
C=1.0, # 규제 강도 설정 (값이 작을수록 규제가 강해짐)
fit_intercept=True, # 절편을 계산할지 여부 설정
intercept_scaling=1, # 절편에 대한 스케일링 조정
class_weight=None, # 클래스 가중치 설정 (None: 모든 클래스에 동일한 가중치)
random_state=None, # 랜덤 넘버 시드 설정 (None: 난수 발생이 매번 달라짐)
solver='liblinear', # 최적화 알고리즘 설정 (소규모 데이터셋에 적합)
max_iter=100, # 최대 반복 횟수 설정
multi_class='ovr', # 다중 클래스 문제 처리 방식 설정 (One-vs-Rest)
verbose=0, # 학습 과정 출력 여부 설정 (0: 출력 안 함)
warm_start=False, # 이전 학습 결과 재사용 여부 설정 (False: 재사용 안 함)
n_jobs=1 # 사용할 CPU 코어 수 설정 (1: 한 개의 코어 사용)
)
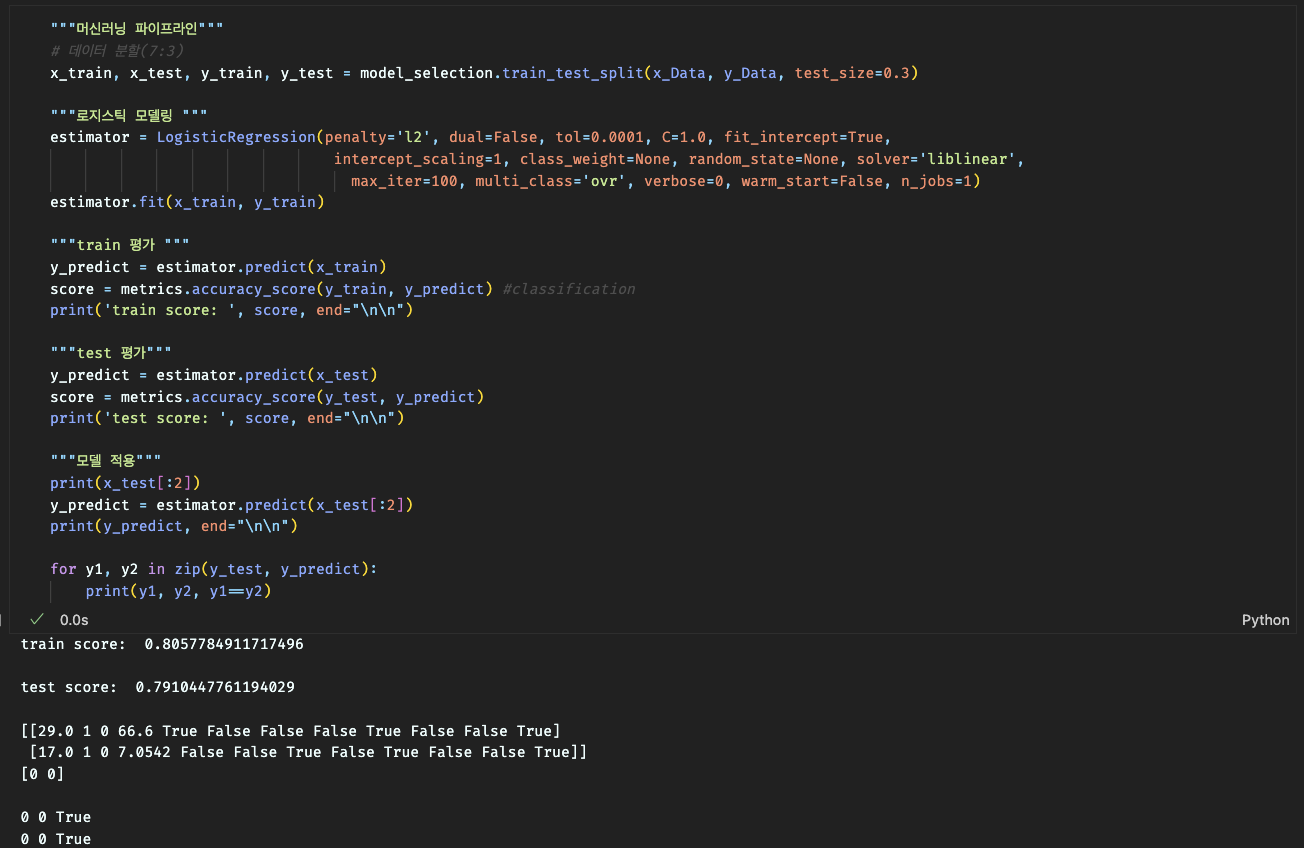
estimator.fit(x_train, y_train) # 모델 학습
# train 평가
y_predict = estimator.predict(x_train) # 학습 데이터 예측
score = metrics.accuracy_score(y_train, y_predict) # 정확도 계산
print('train score: ', score, end="\n\n") # 학습 데이터 정확도 출력
# test 평가
y_predict = estimator.predict(x_test) # 테스트 데이터 예측
score = metrics.accuracy_score(y_test, y_predict) # 정확도 계산
print('test score: ', score, end="\n\n") # 테스트 데이터 정확도 출력
# 모델 적용
print(x_test[:2]) # 테스트 데이터의 첫 두 샘플 출력
y_predict = estimator.predict(x_test[:2]) # 첫 두 샘플에 대한 예측
print(y_predict, end="\n\n") # 예측 결과 출력
for y1, y2 in zip(y_test, y_predict):
print(y1, y2, y1 == y2) # 실제값과 예측값 비교하여 일치 여부 출력
'Python > 빅데이터 분석과 머신러닝' 카테고리의 다른 글
| #10 머신러닝 (1) | 2024.07.30 |
|---|---|
| #9 스몰데이터 통계 (0) | 2024.07.25 |
| #8 데이터 분석 (1) | 2024.07.23 |
| #7 데이터 시각화 (2) | 2024.07.18 |
| #4 데이터 보기(판다스) (0) | 2024.07.17 |