목차
1.시각화
빅데이터 시대에서 데이터를 우리의 눈으로 보기에는 매우 큰 한계가 존재한다. 따라서 데이터 시각화(Data Visualization)는 이 한계를 넘고 매우 효과적으로 정보를 전달하는 수단이 되고 있다.


# 앤스콤 시각화
데이터를 수치적으로만 확인할 때 발생할 수 있는 함정이 있는데 무엇을 말하는 것이냐면 이 데이터 집합들은 기본적인 통계 요약값(평균, 분산, 상관계수, 회귀선 등)이 거의 동일하지만, 시각화해 보면 매우 다른 분포를 보여줍니다. 이는 데이터 분석에서 단순히 통계 요약값에 의존하는 것의 위험성을 강조하기 위해 생겼다. 즉, 데이터 수치에 의존해서 의사결정을 하는 것뿐만 아니라 시각화를 통해 한 번 더 검증을하는 것이 중요하다는 것이다.







시각화 하기



2.기본 시각화
Matplotlib는 많은 파이썬 라이브러리 중에서 플롯(그래프)을 그릴 때 주로 쓰이는 2D, 3D 플롯팅 패키지이다.
그리고 대부분의 시각화 모듈은 입력 값으로 데이터프레임 데이터를 사용하며 리스트나 딕셔너리 데이터 형태로도 가능하다.
이외에 파이썬 그래프 갤러리를 참고하여 많은 그래프를 만들어보자.

# 시각화 준비

# 시각화 옵션 지정
1) 제목
제목을 함수로 추가하는데 한글 폰트는 따로 설정해야지만 나온다.

2) 범례
범례(legend)는 두 개 이상의 데이터를 표시할 때 사용한다.

3) 색상

4) X, Y축 이름
각 축 이름을 지어주자.

5) 그래프 선 모양

6) 그림 범위 지정
그림을 출력하다보면 몇몇 점들은 그림의 범위 경계선에 있어서 잘 안보이는 경우가 있다.
따라서 그림의 범위를 수동으로도 지정하는데 xlim과 ylim 명령어를 사용하며 이 명령들은 그림의 범위가 되는 x축, y축의 최솟값과 최댓값을 지정한다.


| Tips | |||
| 마커 | 뜻 | 마커 | 뜻 |
| o | circle, 원 | b | blue |
| v | triangle_down, 역삼각형 | g | green |
| ^ | triangle_up, 삼각형 | r | red |
| s | square, 네모 | c | cyan |
| + | plus, 플러스 | m | magenta |
| . | point, 점 | y | yellow |
| k | black | ||
| w | white | ||
# 일차 시각화
판다스는 내장 그래프 도구를 활용하여 간단히 데이터를 시각화할 수 있다.
| 옵션 | 그래프 | 옵션 | 그래프 |
| line | 선그래프 | kde | 커널 밀도 그래프 |
| bar | 수직 막대그래프 | area | 면적그래프 |
| barh | 수평 막대그래프 | pie | 파이 그래프 |
| hist | 히스토그램 | scatter | 산점도 그래프 |
| box | 박스플롯 | hexbin | 고밀도 산점도 그래프 |










3.고급 시각화
matplotlib와 seaborn은 단순한 일을 쉽게, 복잡한 일은 가능하게한다.
seaborn은 matplotlib를 기반으로 하는 파이썬 시각화 라이브러리이며, 좀 더 동적인 시각화가 특징이다.
seaborn의 경우 matplotlib보다 기본 색상표가 더 뛰어나기 때문에 색 표현력이 더 좋다.
matplotlib로 그래프를 선언하더라도 sns.set()을 미리 선언해주면 자동으로 시본 기본 팔레트가 출력된다.
| matplotlib | seaborn |
 |
 |
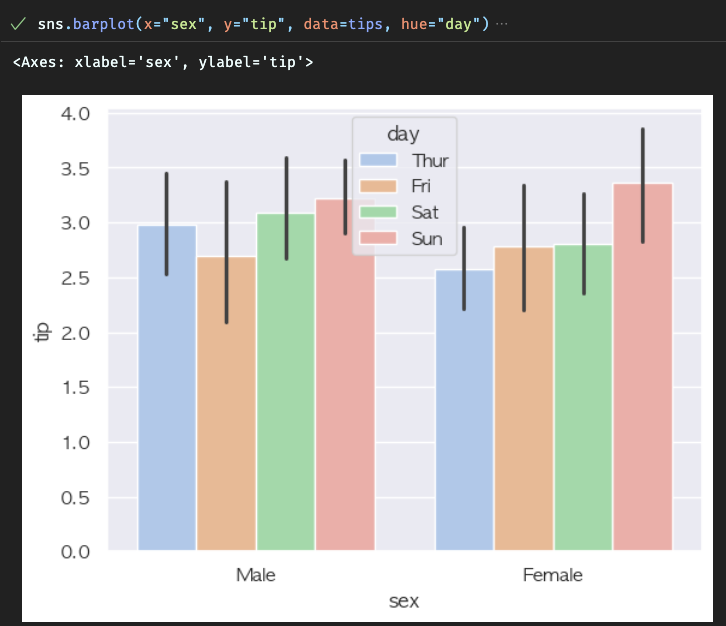
| hue 속성을 넣어주지 않으면 색이 제대로 지정되지 않는다. x축, y축 어떤 것을 기준으로 잡을지 hue한테 주면된다. |


아 참고로 예전 책을 보고 공부하다 보니 함수가 바뀐 것이 많다.
#막대 그래프
"""길이(len) 값을 사용하는 barplot"""
sns.barplot(x="sex", y="tip", data=tips, estimator=len ,hue="sex")
plt.show()
"""합계(sum) 값을 사용하는 barplot"""
sns.barplot(x="sex", y="tip", data=tips, estimator=sum, hue="sex")
plt.show()
"""중앙값(median) 값을 사용하는 barplot"""
sns.barplot(x="sex", y="tip", data=tips, estimator=np.median, hue="sex")
plt.show()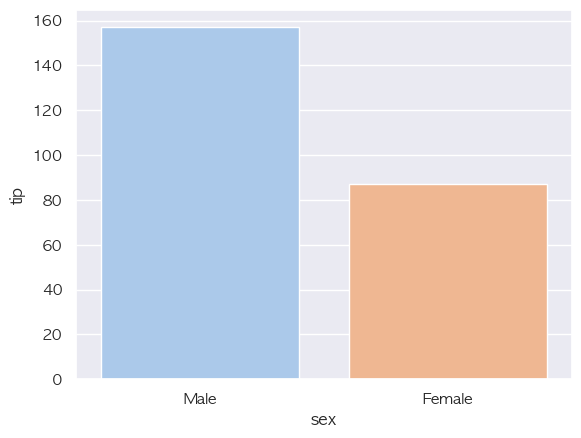




# 박스 플롯
박스 플롯의 제대로된 명칭은 상자 수염 그림이라고 한다. 존터키 아저씨가 데이터 분포를 표현하기 위해 시각적 방법으로 만든 탐색적 그래프이다.
|
 |
예제: 학생들의 시험 점수100명의 학생들이 시험을 봤다고 가정해봅시다. 학생들의 점수를 분석하여 데이터를 시각화해보겠습니다.제1사분위수(Q1):이 값은 학생들의 점수를 낮은 순서대로 나열했을 때, 하위 25%에 해당하는 학생의 점수입니다. 예를 들어, Q1이 60점이라면, 100명의 학생 중 25명은 60점 이하를 받았습니다.제2사분위수(Q2, 중앙값):이 값은 학생들의 점수를 낮은 순서대로 나열했을 때, 중간에 위치한 학생의 점수입니다. 예를 들어, Q2가 70점이라면, 100명의 학생 중 절반인 50명은 70점 이하를, 나머지 50명은 70점 이상을 받았습니다.제3사분위수(Q3):이 값은 학생들의 점수를 낮은 순서대로 나열했을 때, 상위 25%에 해당하는 학생의 점수입니다. 예를 들어, Q3이 80점이라면, 100명의 학생 중 75명은 80점 이하를 받았고, 나머지 25명은 80점 이상을 받았습니다.IQR (Inter Quartile Range):IQR은 Q1과 Q3의 차이로, 중앙 50% 학생들의 점수 범위를 나타냅니다. 예를 들어, Q1이 60점, Q3이 80점이라면 IQR은 20점입니다. 이는 중앙 50%의 학생들이 60점에서 80점 사이의 점수를 받았다는 것을 의미합니다.최솟값:최솟값은 Q1에서 1.5 IQR을 뺀 값입니다. 이 값보다 낮은 점수는 이상치로 간주됩니다. 예를 들어, Q1이 60점, IQR이 20점이라면, 최솟값은 60 - (1.5 * 20) = 30점입니다. 30점 이하의 점수를 받은 학생들은 이상치로 간주됩니다.최댓값:최댓값은 Q3에서 1.5 IQR을 더한 값입니다. 이 값보다 높은 점수는 이상치로 간주됩니다. 예를 들어, Q3이 80점, IQR이 20점이라면, 최댓값은 80 + (1.5 * 20) = 110점입니다. 그러나, 시험 점수는 100점을 초과할 수 없으므로, 실제 최댓값은 100점이 됩니다. 100점 이상의 점수를 받은 학생들은 이상치로 간주됩니다.시각화:
해석:
|
 |
이상치 제거전 시각화 |
| 최솟값: 47.8191910152849 제1사분위수(Q1): 65.16095841652228 제2사분위수(Q2): 70.9436841421238 제3사분위수(Q3): 76.72213668401386 IQR: 11.561178267491584 최댓값: 94.06390408525124 |
4.변수 유형별 시각화
| 변수 | 변수 | 분석 | 시각화 추천 |
| 일변수 | 범주형 | 빈도분석, 교차분석 | 카운터플롯 |
| 연속형 | 기술통계 | 히스토그램 | |
| 이변수 | 연속형/연속형 | 상관분석 | 스캐터플롯 |
| 범주형/범주형 | 카이제곱 | 히트맵 | |
| 범주형/연속형 | 다변량분석 | 바이올린, 스트립플롯 스웜플롯 |
|
| 다변수 | 연속형 3개 | 다변량 분석 | |
| 연속형 일변수, 범주형 이변수 |
다변량 분석 |
https://python-graph-gallery.com/
Python Graph Gallery | The Python Graph Gallery
The Python Graph Gallery displays hundreds of charts made with Python, always with explanation and reproduciible code
python-graph-gallery.com
#일변수 시각화



'Python > 빅데이터 분석과 머신러닝' 카테고리의 다른 글
| #9 스몰데이터 통계 (0) | 2024.07.25 |
|---|---|
| #8 데이터 분석 (1) | 2024.07.23 |
| #4 데이터 보기(판다스) (0) | 2024.07.17 |
| #6 데이터 탐색 (1) | 2024.07.14 |
| #5 데이터 클렌징 (1) | 2024.07.14 |