목차
1. 데이터 클렌징(Data Cleansing)
데이터 분석에서 데이터의 특정 편향(Bias)이 없으며 명확하고 깨끗한 데이터를 확보하는 작업을 데이터 클렌징이라고 한다.
데이터 클린징은 전체 데이터 분석에서 많은 부분을 차지할 정도로 중요하면서도 손이 많이 가는 일이다.
2차 세계대전이 끝나가던 시기 연합군은 무사 귀환 비행기들을 대상으로 비행기의 어느 부위에 적의 총알이 집중되었는지를 조사했고 그 결과로 꼬리날개, 몸통 중앙, 앞날개 양쪽을 제외한 부분에 총탄이 집중되었다는 것을 알고 대비책으로 강판을 추가로 부착하여 비행기의 안전성을 확보하고자 했지만 아브라함 월드는 이에 대해 반대 주장을 했습니다. 아브라함 월드는 총탄이 맞지 않은 부분을 강화해야 한다는 것이었는데 실제로 위의 데이터의 경우 무사 귀환한 비행기들로만 분석 범위를 제한하는 실수가 발생한 거였습니다.
귀환하지 못한 비행기들은 전문가들이 예상하지 못한 부분에 공격을 받았고 이 때문에 비행기가 추락했을 가능성이 더 높았던 것입니다.
따라서 이러한 이야기는 통계학에서 생존자 편향(Survivor Bias) 또는 표본 편향(Sample Bias) 오류의 대표적인 사례이다.
이처럼 원 데이터(Raw Data)를 바로 분석에 사용할 수 있는 경우는 많지 않고 또한 데이터의 양이 많아질수록 클렌징 작업은 더욱더 어려워진다.
2. 결측 데이터
데이터를 확보하고 데이터 전처리에서 먼저 해야할 일은 데이터 클렌징이다. 데이터 클렌징 작업으로 데이터에서 누락된 값 즉, 결측값(Missing Data)가 있는지를 확인한다. 이러한 결측값이 있는 상태에서 분석을 하게 된다면 왜곡된 결과가 나올 수 있다보니 정확성이 떨어집니다. 결측값이 발생하는 유형은 다양하며 어떠한 유형인지에 따라 결측값 처리 여부의 방법도 달라집니다.
우리가 사용하는 판다스에서는 결측값을 'NaN(Not a Number)'으로 표기하며, 'None'도 같은 결측값을 말한다.
결측값을 처리하는 방법에는 크게 두 가지가 있는데 제거(Deletion)와 대체(Imputation) 이다.
제거 : 말 그대로 결측값을 포함하는 행과 열을 삭제하는 것.
대체 : 특정한 방법, 대표가되는 값인 평균으로 값을 변환하는 등..
그럼 어떻게 보고 삭제하고 대체하냐 인데...
데이터가 매우 많고 결측값이 별로 없는 경우에는 결측값이 들어있는 행 전체를 삭제하고 분석을 진행하거나 특정 변수의 결측값의 결측값 비율이 매우 높고, 결측값을 바꿀 특별한 방법이 없는 경우 신뢰성의 확보를 위해 그 변수(행, 컬럼)을 삭제하고 분석을 진행하기도 합니다.
결측 데이터 처리
1. 결측 데이터 확인



결측 데이터 개수 확인

행 단위 결측값 개수 확인
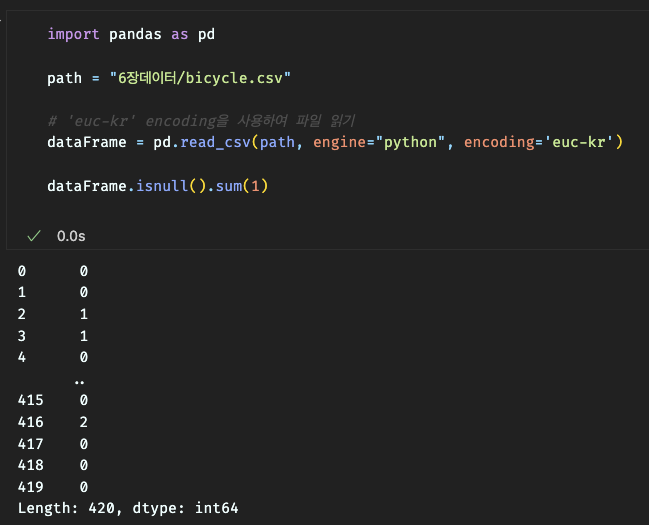
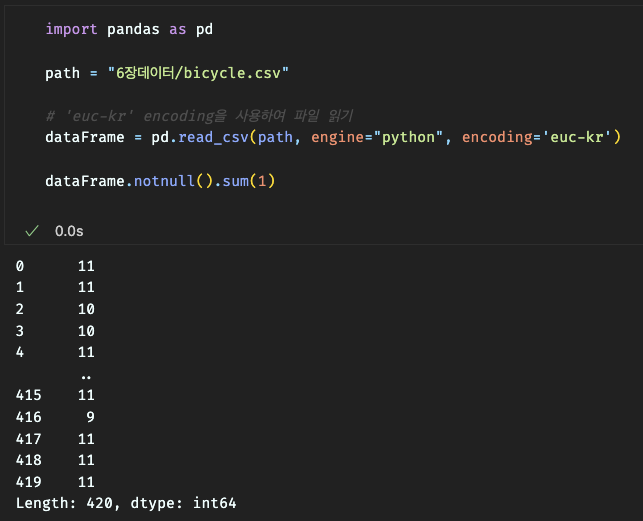
행 단위 실젯값 개수 확인
2.결측 데이터 제거
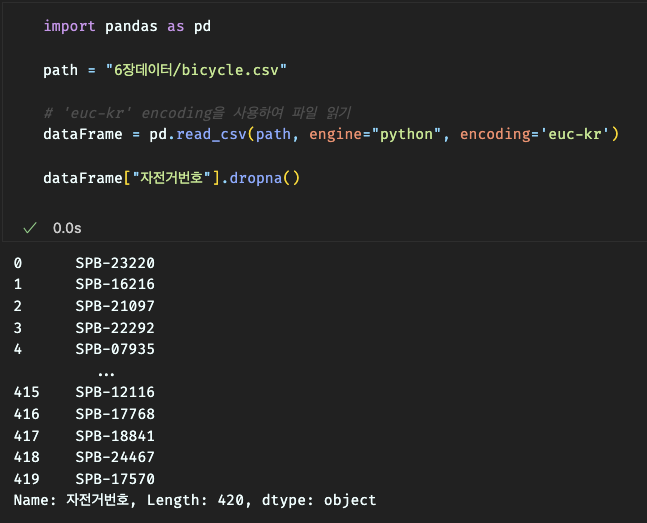
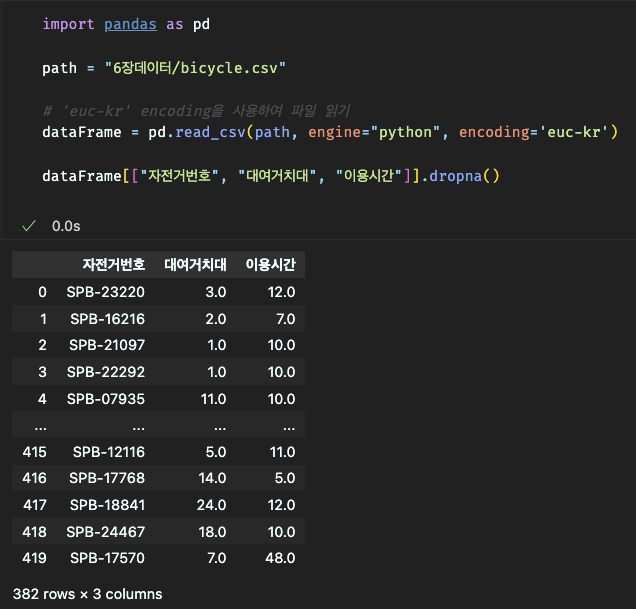
결측값이 들어있는 행, 열 전체 또는 특정 행, 열만이 제거가 가능하다.
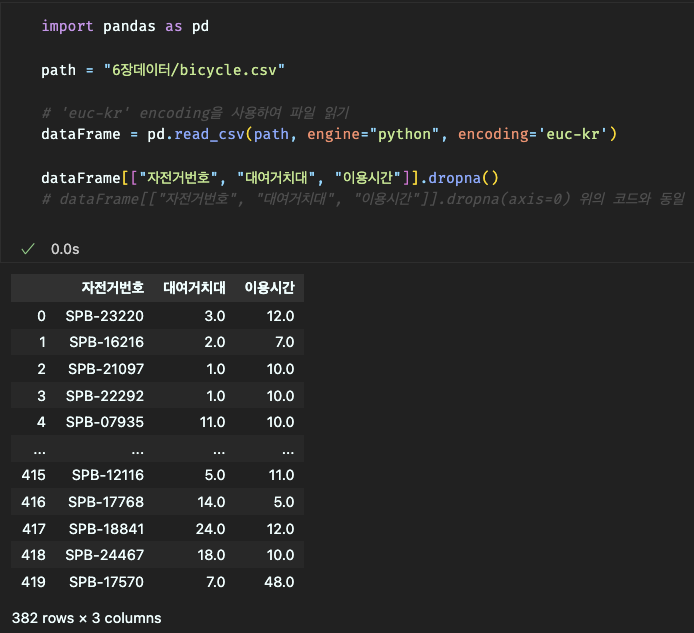
dropna() 함수를 사용하여 결측값이 들어있는 행 전체(axis=0) 삭제,
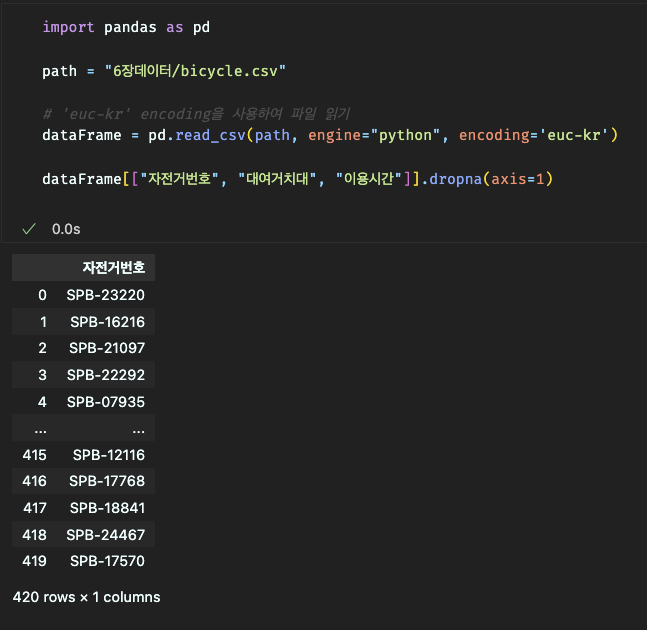
dropna() 함수를 사용하여 결측값이 들어있는 열 전체(axis=1) 삭제,
또는 특정 행, 열 만을 대상으로 결측값이 들어 있으면 제거할 수 있다.
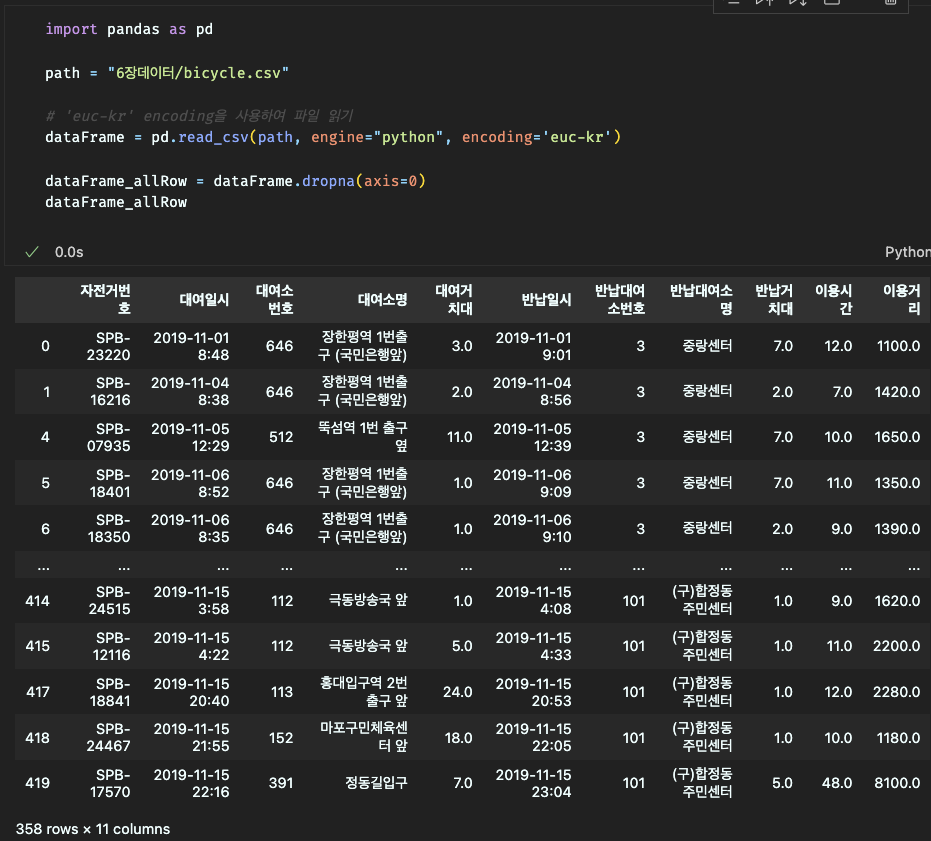
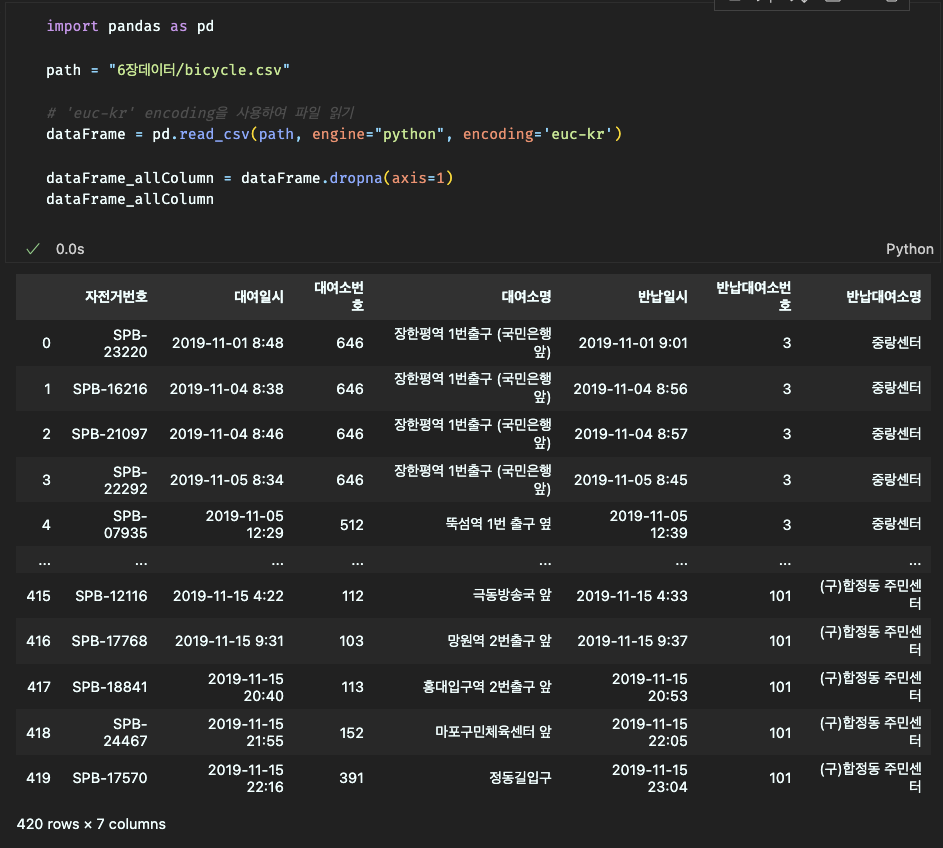
특정 열, 행 제거
2.결측 데이터 대체
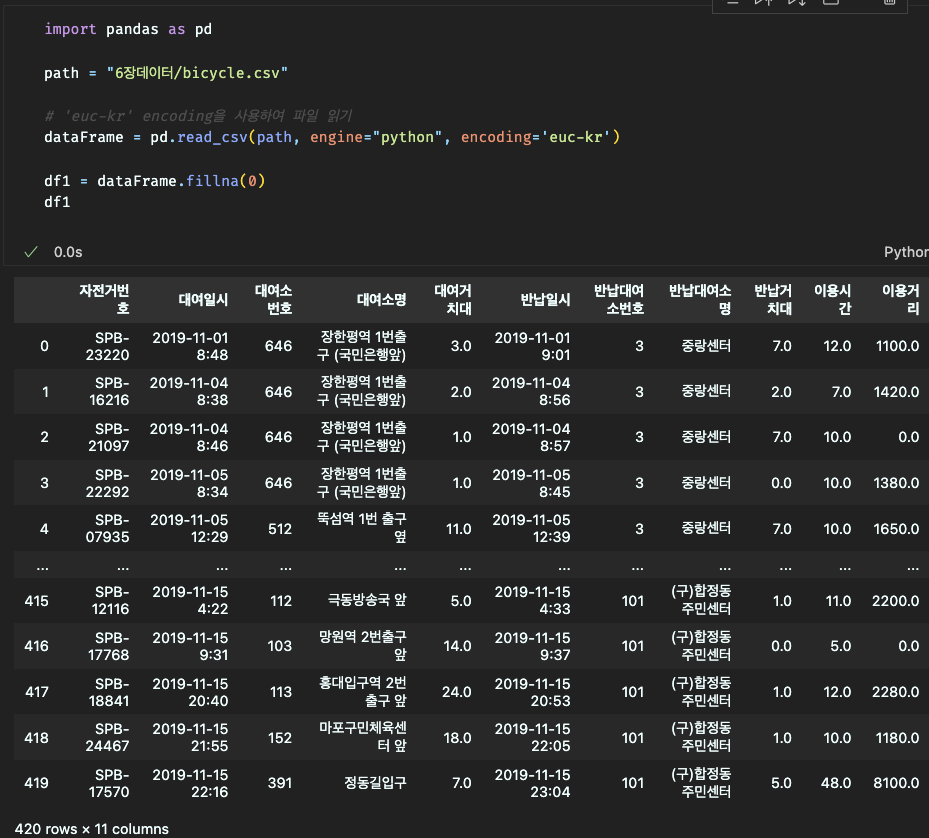
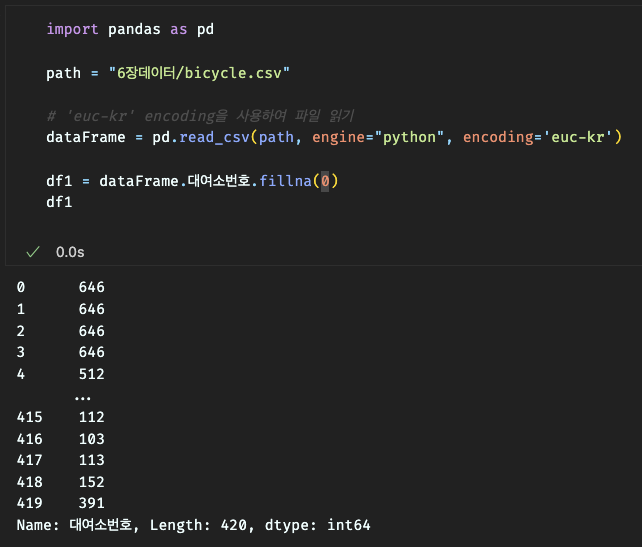
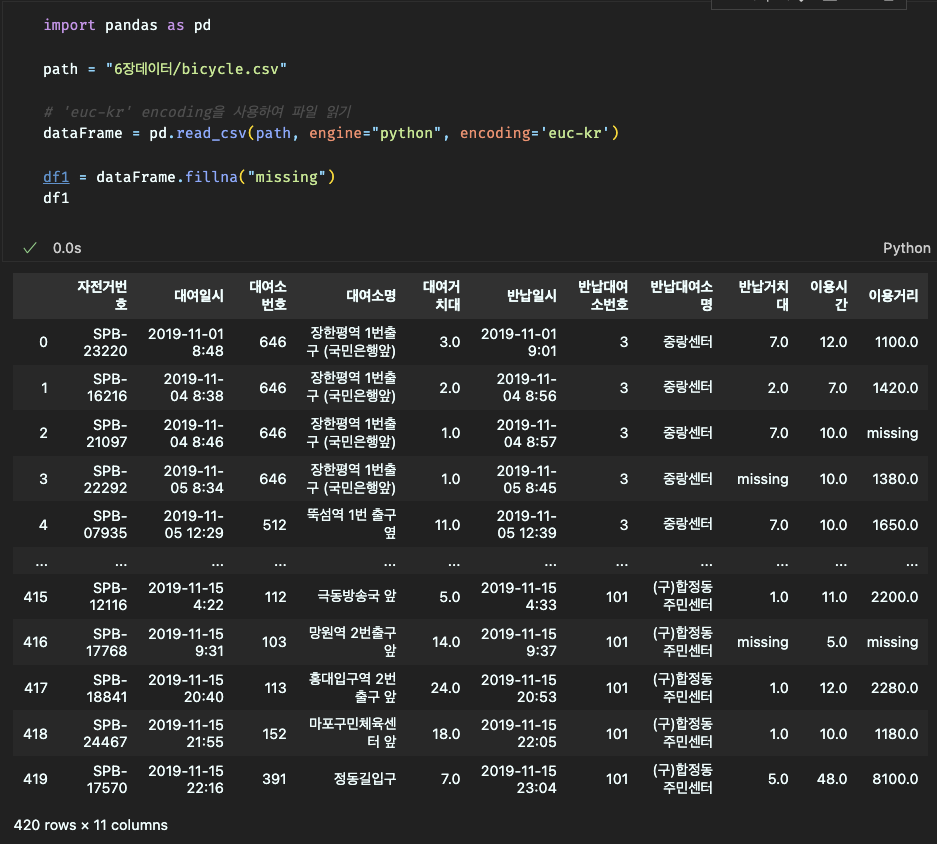
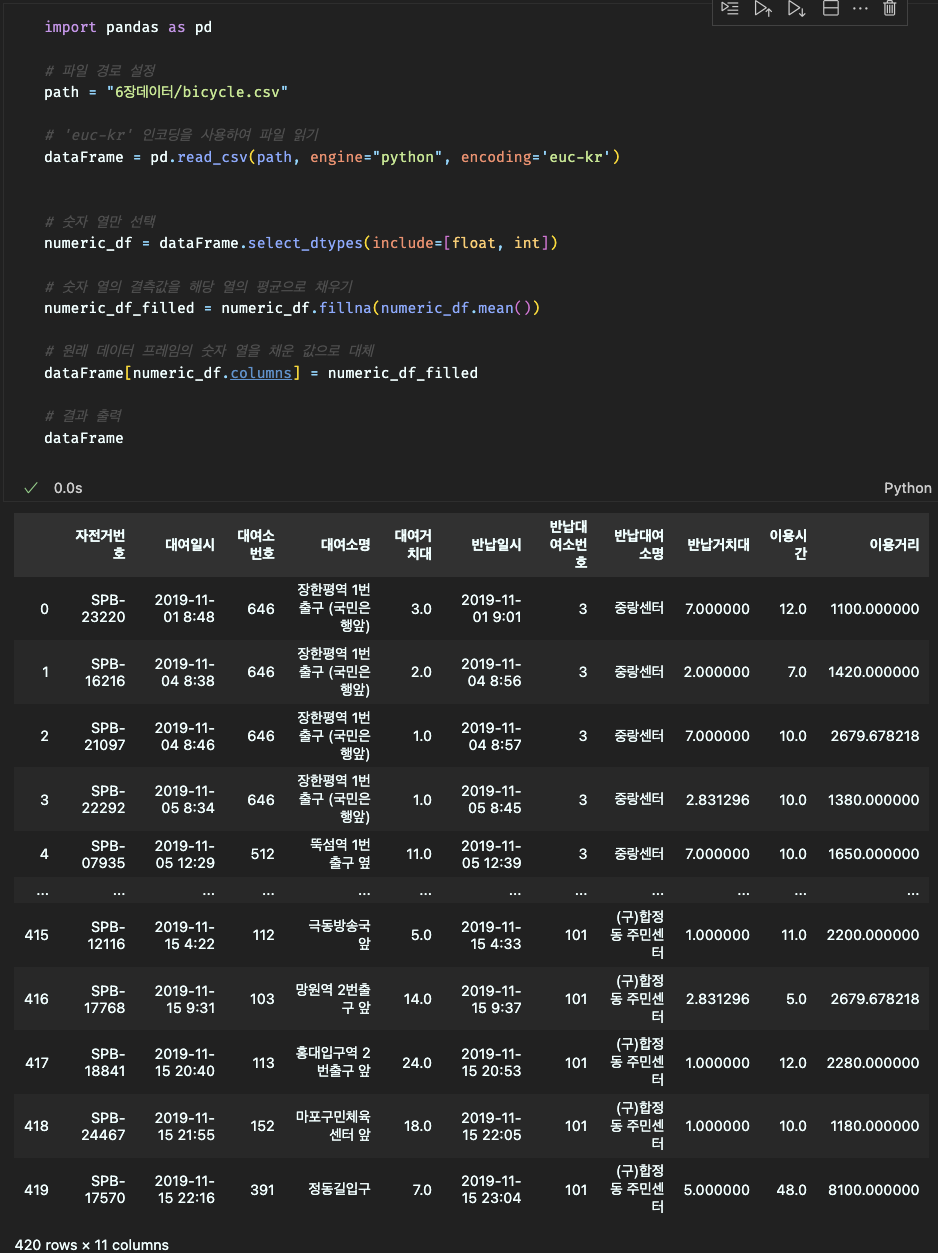
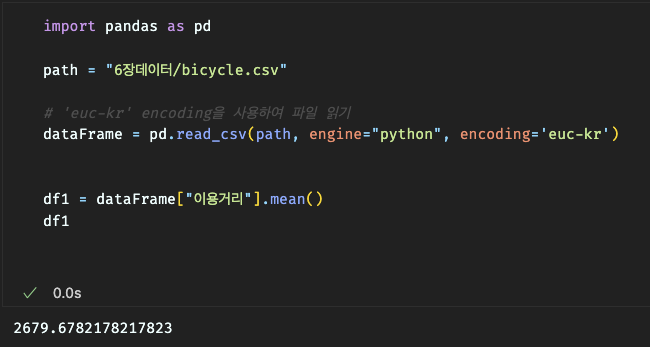
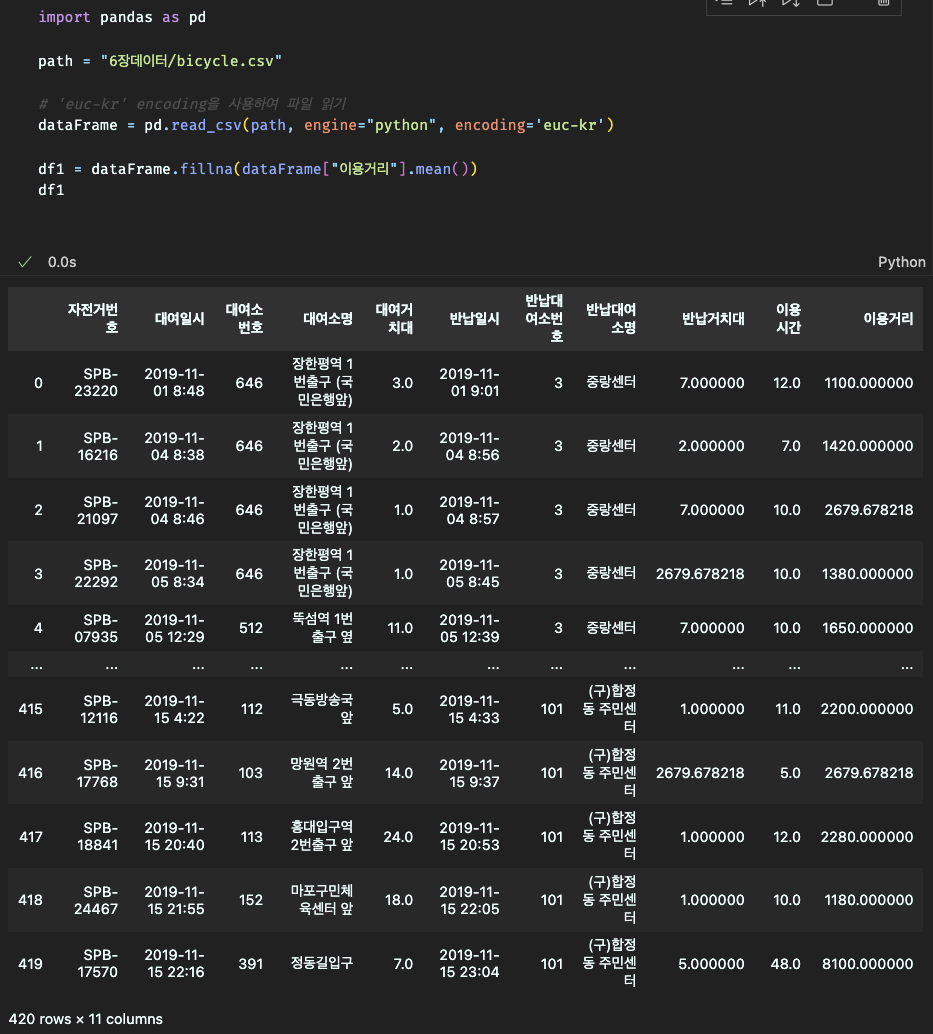
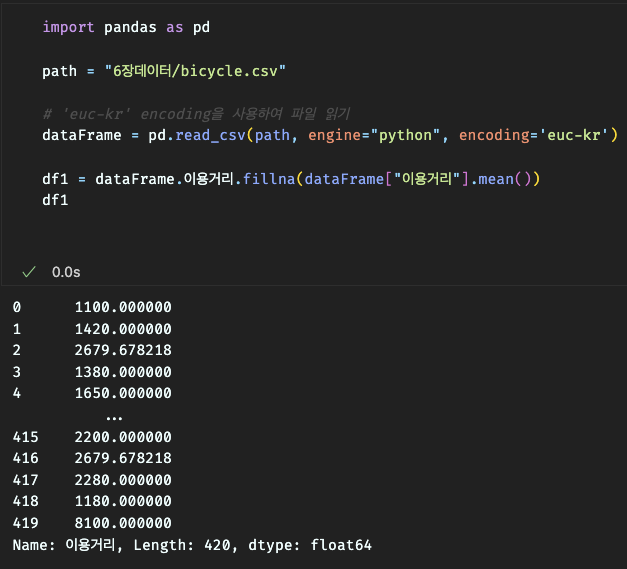
3.결측 데이터 반영 확인
| 결측 데이터 처리할 때 주의해야할 사항 1.Null의 의미 숫자 0과 null은 같은 완전히 다른 개념이다. 0은 -1과 1사이의 숫자(정수)이지만 null은 알 수 없는 미지의 값 또는 미정 값이다. 2.자료형 결측 데이터가 포함된 데이터 파일을 데이터프레임으로 처리할 때는 자료형에 주의해야한다. 실수형, 정수형, 날짜/시간 자료형을 주의하자. 문자열의 경우에는 빈 문자열이나 데이터 없음(NA)을 별도의 범주형 값으로 사용하자. 3.Null은 연산 시 주의해야한다. sum(), cumsum() 함수는 계산 시 NaN은 '0'으로 간주하고 처리한다. 실수형은 NaN 값을 이용하여 누락 데이터를 표시가 가능하다. 정수형은 NaN 값이 없기 때문에 실수로 자동 변환한다. 날자 자료형은 parse-dates 인수로 날짜 시간형 파싱을 진행해야 datetime64 자료형이 되어 누락 데이터가 NaT 값으로 나타난다. 4.결측치 제거를 위해 들어있는 행, 열 전체를 삭제하는 것은 왜곡의 위험성이 있기 때문에 주의하자. |
3. 이상 데이터
정상 범위를 벗어난 데이터를 이상치(Outlier)라고 한다. 대부분의 데이터가 정상적일 수도 있지만 모두가 그렇지는 않을 수 있다.
여기서 이상한(비정상적인) 데이터를 검출하는 것을 이상 탐지(Anomaly Detection)이라고 한다.
이는 데이터 마이닝의 일부이며, 자료에서 예상과는 다른 패턴을 보이는 개체 또는 자료를 찾는 것을 말합니다.
밑에 사진을 보면 데이터들이 서로 밀접하게 모여있는 것은 클러스터링이 되어있는 것은 일반적인 데이터이지만 42070과 같이 따로 떨어져있는 데이터는 이상 데이터로 의심해봐야한다.
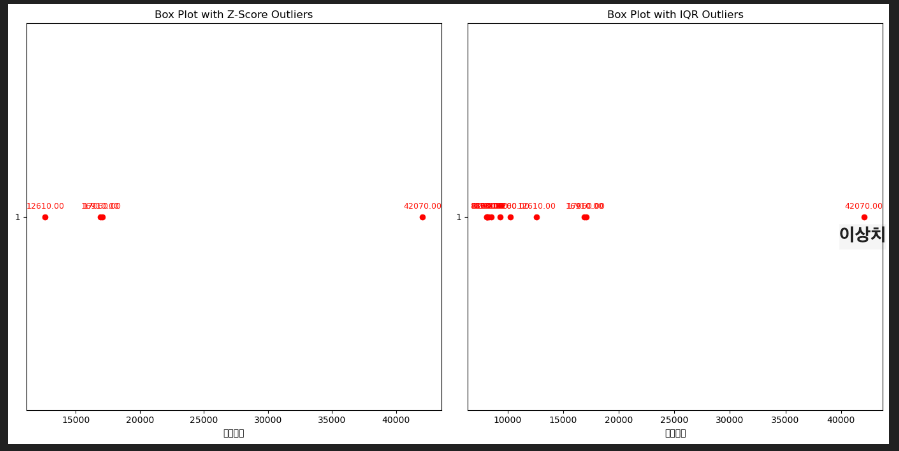
# 이상 데이터 확인
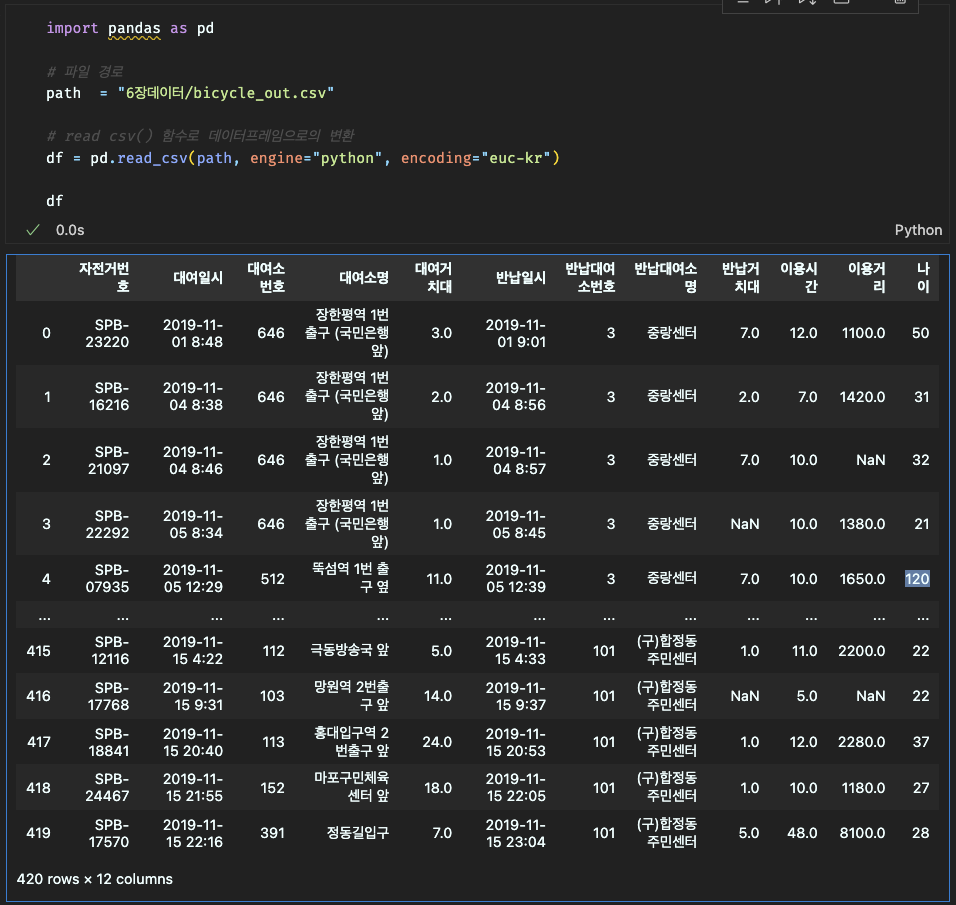
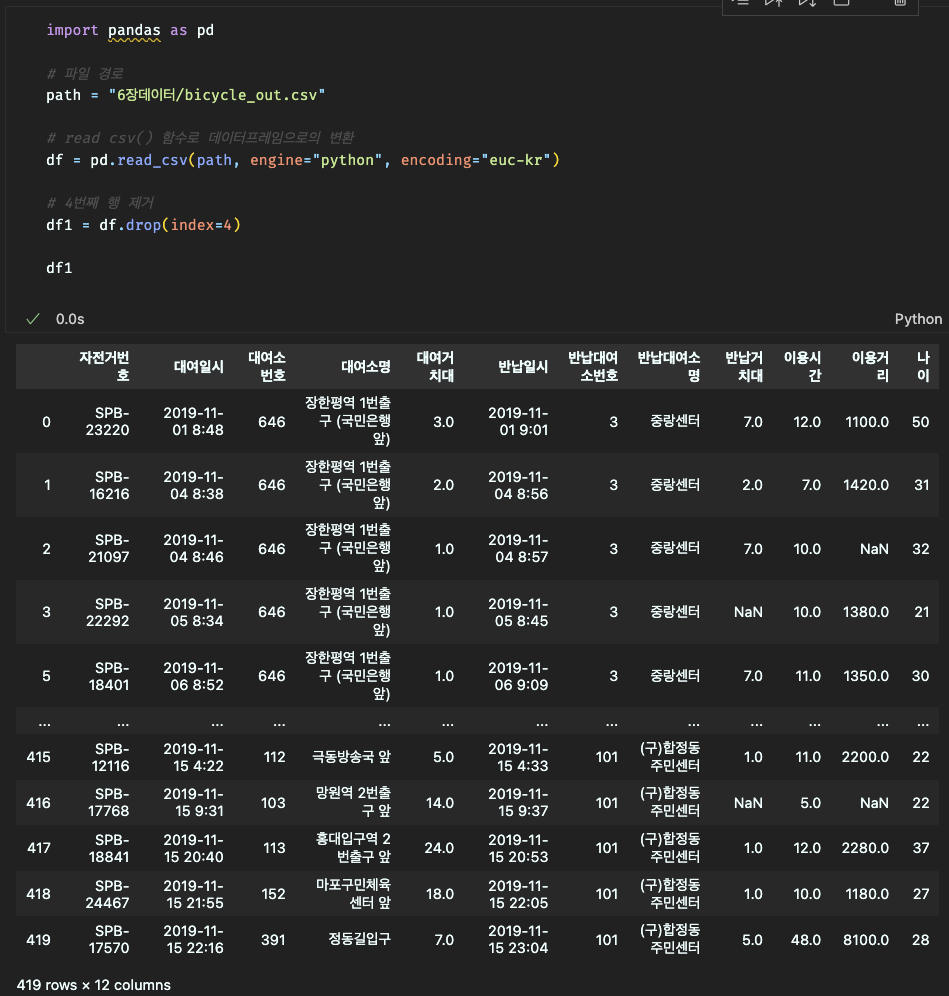
# 이상 데이터 시각화
데이터량이 많은 것을 분석할 때 이상 데이터를 눈으로 발견하기에는 매우 쉽지 않다. 이런 경우 시각화를 위해 박스플롯을 이용하는데
- 중앙값(Median)은 중앙값 50%에 위치한 데이터를 말한다.
중앙값은 짝수일 경우 2개가 될 수 있고 이것이 평균 중앙값이 될 수 있다. 홀수일 경우에는 1개다. - 박스(Box)는 25%(Q1)~75%(Q3)까지의 값들을 박스로 둘러싼다.
- 수염(Whisker)은 박스의 각 모서리(Q1, Q3)로부터 IQR의 1.5배 내에 있는 가장 멀리 떨어진 데이터점까지 이어져 있는 것을 말한다.
- 이상치(Outlier)는 수염보다 바깥쪽에 데이터가 존재하는 데이터로 이것을 이상치로 분류한다.

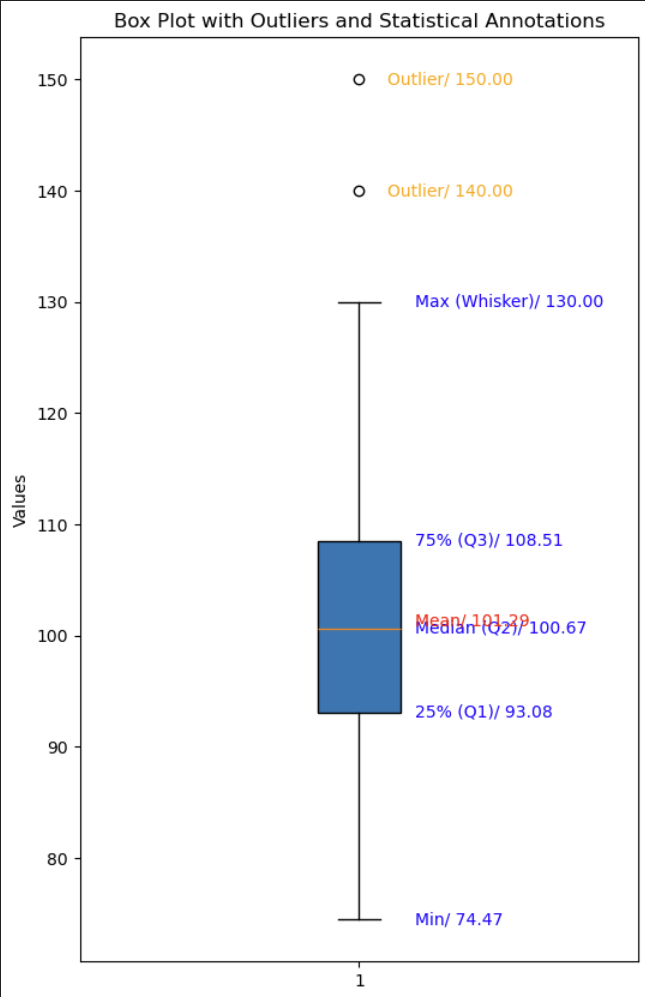
이용시간 이상치 시각화
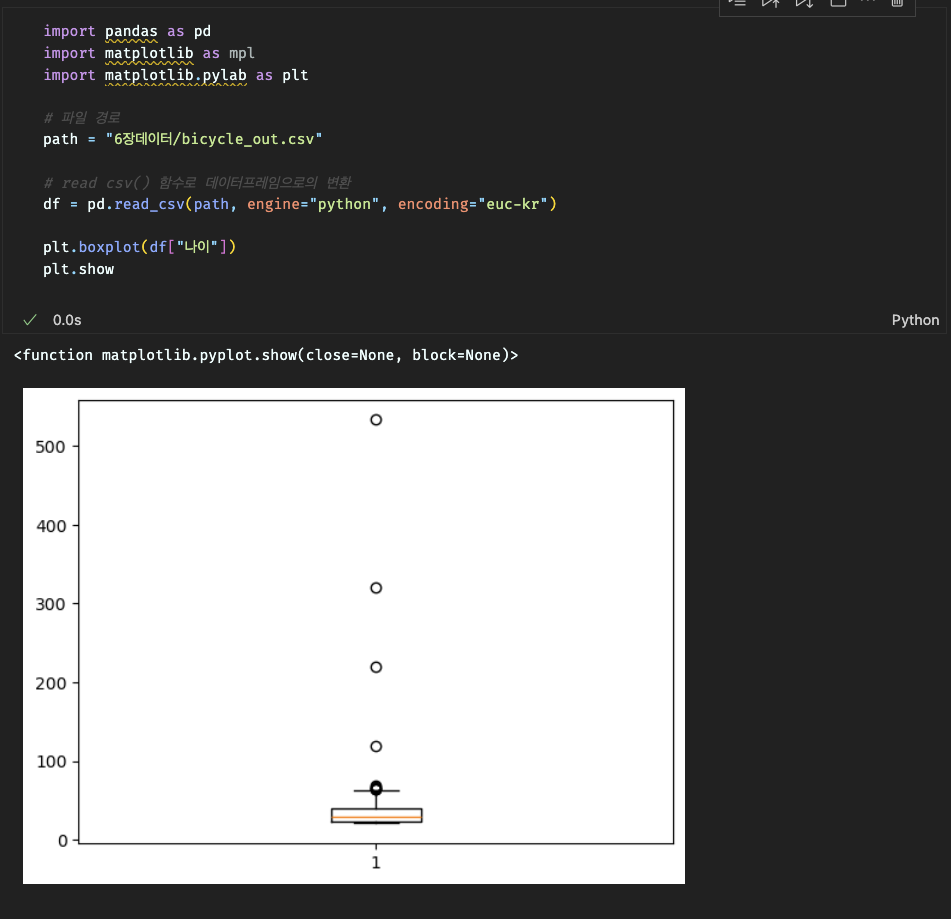
이상 데이터 처리 방법
1. 단순 삭제 (Deleting)
상황: 이상치가 데이터의 일부로 포함되어 있지만, 해당 데이터를 분석 목적에서 완전히 배제할 수 있는 경우 사용합니다.
사용 예시:
- 예시 1: 데이터셋에서 이상치가 실수로 입력된 경우, 분석 목적에 부합하지 않을 수 있습니다. 예를 들어, 온도 데이터에서 천재지변으로 인한 극단적인 기온 데이터가 포함된 경우.
- 예시 2: 실험 데이터에서 실험 오류로 인해 발생한 이상치가 분석 결과에 부정적인 영향을 미칠 수 있는 경우.
적용 방법: 해당 이상치를 데이터셋에서 삭제하고, 이후 분석을 진행합니다. DataFrame에서 drop() 메서드를 사용하여 이상치를 삭제할 수 있습니다.
2. 다른 값으로 대체 (Imputation)
상황: 이상치가 부정확하게 기록되었지만, 해당 데이터를 단순히 삭제하기보다는 대체할 수 있는 경우 사용합니다.
사용 예시:
- 예시 1: 결측치 대체와 비슷하게, 일부 이상치가 존재할 때 이를 평균, 중앙값 또는 다른 측정값으로 대체하여 데이터셋의 왜곡을 최소화합니다.
- 예시 2: 특정 범주 데이터에서 잘못된 값이 포함된 경우, 해당 값들을 해당 범주의 평균 또는 대표값으로 대체할 수 있습니다.
적용 방법: Pandas의 fillna() 메서드나 간단한 계산을 사용하여 이상치를 대체합니다. 예를 들어, 평균값이나 중앙값으로 대체할 수 있습니다.
3. 변수화 (Feature Engineering)
상황: 이상치가 원본 데이터에 포함되어 있지만, 특정 변수로 설명할 수 있는 경우 사용합니다.
사용 예시:
- 예시 1: 데이터에서 범주를 정의하는 변수가 있을 때, 이상치를 해당 범주로 변환하여 특정 극단값을 설명하는 데 사용합니다.
- 예시 2: 수치적 데이터에서 잘못된 측정치가 있을 경우, 이를 해당 변수의 범주로 변환하여 특정 상황을 설명하는 데 사용할 수 있습니다.
적용 방법: 새로운 변수를 생성하여 이상치를 설명할 수 있는 범주화 작업을 수행합니다. 이는 데이터를 해석 가능한 형태로 변환할 수 있습니다.
4. 리샘플링 (Resampling)
상황: 데이터셋에 이상치가 포함되어 있지만, 이러한 이상치가 노이즈로 인식될 수 있는 경우 사용합니다.
사용 예시:
- 예시 1: 시계열 데이터에서 극단적인 이상치가 있는 경우, 이를 평활화하거나 다시 샘플링하여 극단값의 영향을 줄일 수 있습니다.
- 예시 2: 머신러닝 모델에서 특정 데이터 포인트가 지나치게 높거나 낮은 값으로 인식될 때, 데이터셋을 다시 샘플링하여 모델의 안정성을 높일 수 있습니다.
적용 방법: 시계열 데이터의 경우, 평균화 기법을 사용하거나 다시 샘플링하여 이상치의 영향을 줄일 수 있습니다. 이는 데이터셋을 보다 안정적으로 만듭니다.
5. 케이스 분리 분석 (Case-Specific Analysis)
상황: 이상치가 특정 경우에만 적용되는 경우, 해당 케이스를 분리하여 개별적으로 분석하는 경우 사용합니다.
사용 예시:
- 예시 1: 특정 지역에서만 발생하는 이상치가 있는 경우, 해당 지역의 데이터를 분리하여 개별적으로 분석하고 처리합니다.
- 예시 2: 고객 데이터에서 특정 고객의 이상치가 발생하는 경우, 해당 고객의 데이터를 개별적으로 분석하여 대응합니다.
4. 중복 데이터
데이터를 수집하는 과정 또는 데이터를 병합하는 단계에서 오류 등으로 인해 데이터가 중복이 되는 경우가 생길 수 있는데...
특히, 유일함을 가진 키(key)를 관리하는 경우 중복 데이터가 발생하면 악영향을 끼틴다. 따라서 데이터 분석에 들어가기전 중복 데이터를 확인하고 처리하는 데이터 클렌징 작업이 필요하다.
'Python > 빅데이터 분석과 머신러닝' 카테고리의 다른 글
| #4 데이터 보기(판다스) (0) | 2024.07.17 |
|---|---|
| #6 데이터 탐색 (1) | 2024.07.14 |
| #3 데이터 준비 (1) | 2024.07.05 |
| #2 파이썬 데이터 (1) | 2024.07.03 |
| #1 빅데이터와 인공지능(머신러닝) (1) | 2024.07.03 |