데이터 이해
빅데이터 시대가 오면서 수치 중심의 데이터는 기술 발전으로 대량의 텍스트와 이미지, 음성 등 모든 산업 분야에서 만들어지는 빅데이터를 처리할 수 있게 되었다. 데이터는 고정 형식이 아니며 먼저 수집되는 데이터 유형을 확인해야 한다. 유형별 저장 및 처리 기술 별로 데이터를 파악하는 것도 매우 중요하기 때문이다.

데이터 분석을 위한 데이터는 규격화된 형식에 따라 정형(Structured), 반정형(Semi-Structured) 그리고 비정형(Unstructured)으로 분류한다.
1. 정형 데이터 (Structured Data)
정형 데이터는 고정된 필드에 저장되는 데이터로, 데이터베이스와 같은 테이블 형식으로 구조화되어 있습니다. 각 데이터 항목은 정의된 필드(열)에 들어가며, 데이터 유형과 형식이 명확하게 정의되어 있습니다.
특징:
- 고정된 형식: 행(Row)과 열(Column)로 구성된 테이블 형태.
- 명확한 스키마: 데이터베이스 스키마에 따라 데이터 형식이 미리 정의됨.
- 데이터베이스 관리 시스템(DBMS): 주로 관계형 데이터베이스(RDBMS)에서 사용됨.
- 쿼리 언어: SQL과 같은 언어를 사용하여 데이터를 검색, 추가, 수정, 삭제.
예시:
- 데이터베이스 테이블: 고객 정보, 판매 기록, 재고 목록 등.
- 스프레드시트: 엑셀 파일의 시트.
-- 고객 정보를 저장하는 테이블
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Email VARCHAR(100),
PhoneNumber VARCHAR(15)
);2. 반정형 데이터 (Semi-Structured Data)
반정형 데이터는 구조화된 데이터와 비구조화된 데이터의 중간에 위치하는 데이터로, 데이터 항목 간의 구조가 존재하지만 고정된 필드로 정의되지는 않습니다. 일반적으로 태그나 키-값 쌍을 사용하여 데이터의 의미를 정의합니다.
더 쉽게 이야기하자면 특정한 형식에 따라 저장된 데이터이지만 정형 데이터와 달리 형식에 대한 설명을 함께 제공해야 한다. 따라서 구조를 해석하는 파싱(일종의 번역) 과정이 필요하며 파일 형태로 저장됩니다.
특징:
- 유연한 형식: 명확한 스키마 없이 다양한 형식의 데이터 저장 가능.
- 태그와 키-값 쌍: XML, JSON 등과 같은 형식을 사용하여 데이터 구조 정의.
- 자유로운 스키마: 데이터의 구조가 유연하여 다양한 형식의 데이터 포함 가능.
예시:
- XML 파일: 마크업 언어를 사용한 데이터 저장.
- JSON 파일: JavaScript 객체 표기법을 사용한 데이터 저장.
- NoSQL 데이터베이스: MongoDB, CouchDB 등.
{
"고객ID": 123,
"이름": "홍길동",
"성": "도",
"이메일": "hong.gildong@example.com",
"전화번호": "+1234567890",
"주문목록": [
{
"주문ID": 1,
"상품": "노트북",
"수량": 1,
"가격": 1000
},
{
"주문ID": 2,
"상품": "마우스",
"수량": 2,
"가격": 25
}
]
}
--------------------------------
{
"CustomerID": 123,
"FirstName": "John",
"LastName": "Doe",
"Email": "john.doe@example.com",
"PhoneNumber": "+1234567890",
"Orders": [
{
"OrderID": 1,
"Product": "Laptop",
"Quantity": 1,
"Price": 1000
},
{
"OrderID": 2,
"Product": "Mouse",
"Quantity": 2,
"Price": 25
}
]
}3. 비정형 데이터 (Unstructured Data)
비정형 데이터는 고정된 구조나 형식이 없는 데이터로, 텍스트, 이미지, 비디오 등의 형식으로 존재합니다. 이 데이터는 명확한 구조가 없기 때문에 분석이 어렵지만, 중요한 정보가 많이 포함되어 있습니다.
특징:
- 고정된 형식 없음: 데이터 항목 간의 구조가 존재하지 않음.
- 다양한 형식: 텍스트, 이미지, 오디오, 비디오 등.
- 분석 도구 필요: 텍스트 마이닝, 이미지 처리 등의 기술이 필요함.
예시:
- 텍스트 파일: 문서, 이메일, 블로그 게시물.
- 멀티미디어 파일: 이미지, 비디오, 오디오 파일.
데이터 소스
빅데이터 시대에는 다양한 소스에서 엄청난 양의 데이터가 발생합니다. 이러한 데이터 소스는 각각 고유한 특징과 데이터를 제공한다.
데이터 형식과 유형의 다양성만큼 빅데이터 시대에 엄청난 속도로 늘어나는 데이터 발생 소스도 구분해야한다.
| 대표적인 데이터 소스의 종류 | 1) 미디어 2) 클라우드 3) 웹 4) 사물인터넷 5) 데이터베이스 6) 오픈(공공) 데이터 |
1) 미디어
미디어 데이터 소스는 텍스트, 이미지, 비디오, 오디오 등 다양한 형식의 데이터를 포함합니다. 소셜 미디어 플랫폼, 뉴스 웹사이트, 스트리밍 서비스 등이 미디어 데이터의 주요 공급원입니다.
- 예시: 페이스북, 트위터, 유튜브, 넷플릭스, 뉴스 웹사이트
- 특징: 비정형 데이터가 주를 이루며, 실시간으로 데이터가 생성되고 공유됩니다.
2) 클라우드
클라우드 데이터 소스는 클라우드 컴퓨팅 환경에서 생성되고 저장되는 데이터를 포함합니다. 클라우드 서비스 제공업체는 다양한 애플리케이션과 서비스를 통해 데이터를 생성하고 관리합니다.
- 예시: AWS, 구글 클라우드 플랫폼, 마이크로소프트 애저
- 특징: 데이터 저장소의 유연성, 확장성, 접근성 제공. 다양한 유형의 데이터가 클라우드 환경에서 생성되고 관리됨.
3) 웹
웹 데이터 소스는 웹사이트와 웹 애플리케이션에서 생성되는 데이터를 포함합니다. 웹 크롤러나 스크레이퍼를 통해 웹 데이터 수집이 이루어집니다. 모바일을 포함한 웹은 일반인들도 광범위하고 쉽게 액세스 할 수 있는 빅데이터의 거대한 소스이다.
- 예시: 전자상거래 사이트, 블로그, 포럼, 검색 엔진
- 특징: 데이터의 양이 방대하고, 반정형 및 비정형 데이터가 혼합되어 있음.
4) 사물인터넷 (IoT)
사물인터넷 데이터 소스는 센서, 디바이스, 스마트 기기 등에서 생성되는 데이터를 포함합니다. IoT 디바이스는 실시간으로 데이터를 수집하고 전송합니다. 사물인터넷에서 생성된 콘텐츠 또는 데이터들은 사람의 개입이 없어 정확한 정보를 생성하므로 최근 발전을 거듭하고 있는 센서와 함께 데이터 소스의 가장 중요한 부분이다.
- 예시: 스마트 홈 기기, 웨어러블 디바이스, 산업용 센서
- 특징: 실시간 데이터 스트림, 다양한 형식의 데이터 수집 (온도, 위치, 동작 등).
5) 데이터베이스
데이터베이스 소스는 관계형 데이터베이스(RDBMS)와 NoSQL 데이터베이스에서 생성되는 데이터를 포함합니다. 이 데이터는 정형 및 반정형 데이터로 구성됩니다. 기업의 분석 업무의 대부분은 정형 데이터를 차지하는 데이터베이스에서 추출하는데. 일반적으로 ETL(Extract, Transform, Load)의 과정을 통해 데이터를 확보한다.
- 예시: MySQL, PostgreSQL, MongoDB, Cassandra
- 특징: 구조화된 데이터를 체계적으로 저장하고 관리. 트랜잭션 데이터, 고객 정보, 제품 정보 등.
6) 오픈(공공) 데이터
오픈 데이터 소스는 정부나 공공 기관에서 공개적으로 제공하는 데이터를 포함합니다. 이러한 데이터는 누구나 접근하고 사용할 수 있습니다.
- 예시: 정부 통계, 교통 데이터, 기상 데이터, 공공 연구 데이터
- 특징: 무료로 제공되며, 다양한 형식의 데이터 포함 (CSV, JSON, XML 등). 데이터의 신뢰성이 높고, 공공의 이익을 위해 제공됨.
오픈 데이터
1) 타이타닉(Titanic : Machine Learning from Disaster)
예전에 인공지능에 대해 공부할 때 타이타닉을 이용해서 공부한 적이 있다.
타이타닉호 침몰 당시의 승객 명단 데이터가 제공되는데, 생존자의 이름, 나이, 티켓 요금, 생사 여부 등의 정보가 포함되어 있다. 이러한 제공되는 데이터를 통해 생존자의 생사 여부와 다른 데이터들 간의 연관성을 분석하여 생존에 영향을 미치는 요소를 찾아내거나 예측할 때 많이 사용된다.
| 변수명(Variable) | 설명(Description) | 데이터 유형(Data Type) | 데이터 형식(Data Format) |
| Passengerid | 승객 고유 식별자 | 정수형 (Integer) | 정형 (Structured) |
| Survived | 생존 여부 (0 = 사망, 1 = 생존) | 이진형 (Binary) | 정형 (Structured) |
| Pclass | 객실 등급 (1 = 1등석, 2 = 2등석, 3 = 3등석) | 범주형 (Categorical) | 정형 (Structured) |
| Name | 승객 이름 | 문자열 (String) | 정형 (Structured) |
| Sex | 성별 (male, female) | 범주형 (Categorical) | 정형 (Structured) |
| Age | 나이 | 실수형 (Float) | 정형 (Structured) |
| SibSp | 함께 탑승한 형제자매/배우자 수 | 정수형 (Integer) | 정형 (Structured) |
| Parch | 함께 탑승한 부모/자녀 수 | 정수형 (Integer) | 정형 (Structured) |
| Ticket | 티켓 번호 | 문자열 (String) | 정형 (Structured) |
| Fare | 운임 요금 | 실수형 (Float) | 정형 (Structured) |
| Cabin | 객실 번호 | 문자열 (String) | 정형 (Structured) |
| Embarked | 탑승한 항구 (C = Cherbourg, Q = Queenstown, S = Southampton) | 범주형 (Categorical) | 정형 (Structured) |
2) MNIST
영상 인식 분야에서 가장 많이 사용하는 데이터이다. 손 글씨로 작성된 우편 번호를 기계가 자동으로 인식할 수 있도록 하기 위해 미국에서 만든 학습용 데이터이다. MNIST 데이터셋은 0에서 9까지의 숫자를 손글씨로 쓴 28x28 픽셀 크기의 흑백 이미지로 구성되어 있습니다. 총 70,000개의 이미지가 포함되어 있으며, 이 중 60,000개는 학습용(training set)으로, 10,000개는 테스트용(test set)으로 사용된다.
이 데이터셋은 학습 알고리즘을 평가하고 개발하는 데 매우 유용하며, 특히 딥러닝 모델의 성능을 테스트하는 데 자주 사용된다.

| 변수명(Variable) | 설명(Description) | 데이터 유형(Data Type) | 데이터 형식(Data Format) |
| 이미지(Image) | 손글씨 숫자 이미지 | 행렬(Matrix) | 정형(Structured) |
| 라벨(Label) | 이미지에 해당하는 숫자(0~9) | 정수형(Integer) | 정형(Structured) |
데이터 불러오기
사람이 혼자서 데이터 작업을 할 때 만들기는 불가능에 가깝다. 왜냐하면 데이터 양의 방대함, 데이터 수집의 복잡성, 데이터 품질 문제, 법적 및 윤리적 고려사항처럼 많은 고려해야 할 사항과 어려움이 있기 때문이다. 따라서 외부에서 대용량 데이터를 불러와서 사용하는데...
판다스는 다양한 형식의 외부 데이터를 불러와 정형 데이터 구조(데이터프레임)로 변환하는 기능을 사용해 보자.
| 파일 형식 | 설명 | 불러오기 | 쓰기 |
| CSV | 쉼표로 구분된 값 파일. 데이터 교환에 많이 사용됨 | pd.read_csv('파일명.csv') | df.to_csv('파일명.csv', index=False) |
| Exel | 엑셀 스프레드시트 파일 | pd.read_excel('파일명.xlsx') | df.to_excel('파일명.xlsx', index=False) |
| JSON | JavaScript Object Notation 파일. 데이터 전송에 많이 사용됨 | pd.read_json('파일명.json') | df.to_json('파일명.json') |
| SQL | SQL 데이터베이스 파일 | pd.read_sql('쿼리', '연결객체') | df.to_sql('테이블명', '연결객체' |
| HTML | HTML 테이블 데이터 | pd.read_html('파일명.html') | df.to_html('파일명.html') |
| Parquet | 컬럼형 스토리지 파일. 대규모 데이터를 효율적으로 처리 | pd.read_parquet('파일명.parquet') | df.to_parquet('파일명.parquet') |
| HDF5 | 계층적 데이터 형식 파일. 대용량 데이터를 저장 | pd.read_hdf('파일명.h5', '키') | df.to_hdf('파일명.h5', '키' |
| Feather | 이식 가능한 파일 형식. 빠른 읽기와 쓰기를 지원 | pd.read_feather('파일명.feather') | df.to_feather('파일명.feather') |
| Pickle | 파이썬 객체 직렬화 파일 | pd.read_pickle('파일명.pkl') | df.to_pickle('파일명.pkl') |
이것 외에도 더 많다.
CSV 파일
CSV란 Comma-separated Values의 약자로써 CSV 파일은 각 라인의 칼럼들이 콤마로 분리된 텍스트 파일 포맷이다. 형식은 스프레드시트와 데이터베이스에 대한 가장 일반적인 가져오기 및 내보내기 형식이다.
https://data.seoul.go.kr/dataList/OA-15182/F/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
위의 사이트에서 CSV 파일을 다운로드하여 실습을 해보자.
판다스에서는 다양한 파일을 읽어서 데이터를 변환하는 일이 많다. 특히 실습과 같이 CSV 파일을 읽어 데이터프레임으로 변환하여 처리한다. 파일 안의 문자들이 한글인 경우 파이썬은 utf-8로 인코딩을 한 후 데이터 프레임으로 전환해야 한다. 안 할 시 오류 발생.
# 판다스 라이브러리 불러오기
import pandas as pd
import openpyxl
# 파일 경로를 찾고 변수 path에 저장
path = '서울특별시 공공자전거 대여이력 정보_2312.csv'
df = pd.read_csv(path, encoding='CP949')
# 데이터를 출력해 봅니다.
print(df)
--------------------------------------------
# 판다스 라이브러리 불러오기
import pandas as pd
# 파일 경로를 찾고 변수 path에 저장
path = '서울특별시 공공자전거 대여이력 정보_2312.csv'
# 인코딩을 지정하여 데이터프레임 변환 시도
encodings = ['cp949', 'euc-kr']
for enc in encodings:
try:
df = pd.read_csv(path, encoding=enc)
print(f'Success with encoding: {enc}')
break
except UnicodeDecodeError as e:
print(f'UnicodeDecodeError with encoding {enc}: {e}')
except Exception as e:
print(f'Error with encoding {enc}: {e}')
# 데이터를 출력해 봅니다.
print(df)

EXCEL 파일
CSV와 마찬가지로 판다스 데이터 분석의 EXCEL 파일 행과 열은 데이터프레임의 행과 열로 일대일 대응이 된다.
# 판다스 라이브러리 불러오기
import pandas as pd
import openpyxl
# 파일 경로를 찾고 변수 path에 저장
path = '서울특별시 공공자전거 대여정보_201810_01.xlsx'
df = pd.read_excel(path, engine='openpyxl')
# 데이터를 출력해 봅니다.
print(df)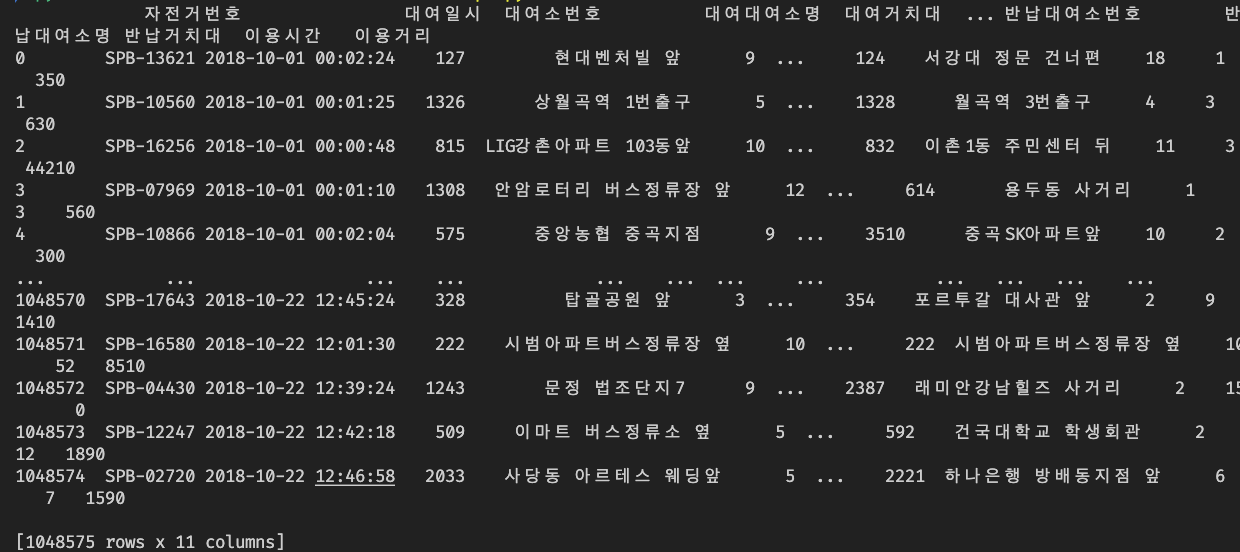
JSON 파일
JavaScript Object Notation의 약자로 자바스크립트 문법에 영향을 받아 개발된 데이터 표현 방식이다.
데이터를 교환하는 한 포맷으로 그 단순함과 유연함 때문에 널리 사용되고 있고 특히 웹 브라우저와 서버 사이의 데이터를 교환하는 데 자주 활용한다. 키-값 쌍으로 대응 관계를 나타내며 딕셔너리 자료구조를 가진다.
# 판다스 라이브러리 불러오기
import pandas as pd
# 파일 경로를 찾고 변수 path에 저장
path = 'example.json'
df = pd.read_json(path, encoding='CP949')
# 데이터를 출력해 봅니다.
print(df)
----------------
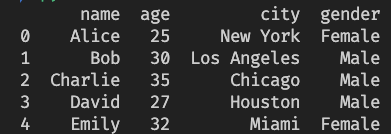
example.json
[
{"name": "Alice", "age": 25, "city": "New York", "gender": "Female"},
{"name": "Bob", "age": 30, "city": "Los Angeles", "gender": "Male"},
{"name": "Charlie", "age": 35, "city": "Chicago", "gender": "Male"},
{"name": "David", "age": 27, "city": "Houston", "gender": "Male"},
{"name": "Emily", "age": 32, "city": "Miami", "gender": "Female"}
]
데이터 저장하기
판다스 데이터프레임은 2차원 배열 구조로 구조화된 데이터이기 대문에 2차원 구조(행과 열)를 갖는 CSV 파일로 변환할 수 있다.
# 판다스 라이브러리 불러오기
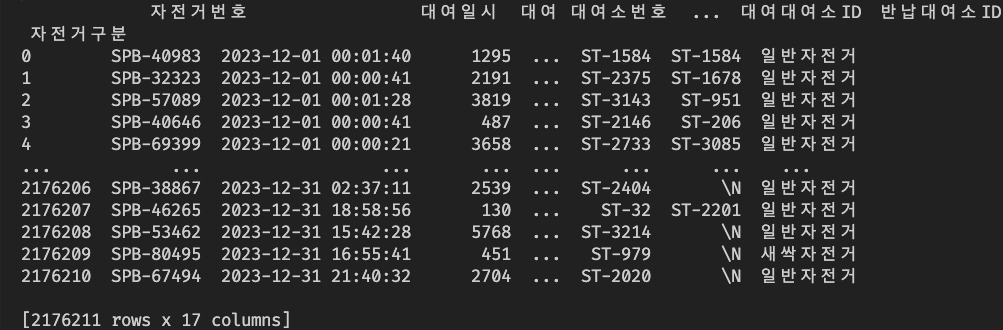
import pandas as pd
# CSV 파일 경로
original_path = '서울특별시 공공자전거 대여이력 정보_2312.csv'
saved_path = '서울특별시.csv'
# CSV 파일 읽기
df = pd.read_csv(original_path, encoding="CP949")
# CSV 파일로 저장
df.to_csv(saved_path, index=False)
# 다시 불러와서 확인
df_reload = pd.read_csv(saved_path)
# 데이터 출력
print(df_reload)

공공 데이터 OPEN API
API는 Application Programming Interface의 약자로 응용 프로그래밍 인터페이스를 의미한다. 다양한 응용 프로그램에서 사용할 수 있는 운영 체제, 혹은 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스이다.
대한민국 공공 데이터 포털에서 제공하는 데이터를 이용해 실습해보자.
우선 위 사이트에 접속하여 회원가입 후 필요한 데이터를 검색한 후 오픈 API 활용 신청을 한 후 발급된 오픈 API 인증키 발급 확인을 한다.
API와 HTTP 프로토콜
인터넷에서 API를 활용하는 기술은 HTTP 프로토콜을 통해 이루어진다. 웹이나 모바일에서 정보를 주고받는 과정은 사용자(클라이언트) 서버의 통신 등 보이지는 않지만 여러 계층과 단계를 진행한다. HTTP 프로토콜에서 정보를 요청(Request)하는 쪽을 클라이언트라고 하며, 정보를 응답(Response)하여 보내는 부분을 서버라고 한다. 이런 구조를 클라이언트/서버라고 한다.
그러면 정보를 요청하는 HTTP 프로토콜의 요청 메시지와 응답 메시지는 어떤 구조로 이루어져 있는가 궁금할 수 있다.
요청 메시지와 응답 메시지 둘 다 메시지 헤더와 메시지 바디로 이루어져 있어 요청하는 메시지 헤더는 요청하는 방식, URI(경로), 프로토콜 버전, 헤더 필드로 구성되어 있습니다. 또한 메시지는 GET과 POST 두 가지 방식으로 요청할 수 있습니다.
두 방식의 가장 큰 차이점은 GET은 UTL(경로)에 데이터를 명시하여 보내지만 POST는 숨겨서 보낸다는 점입니다.
| 인터넷 브라우저 -> | (GET방식) http://hello.com?data=123 -> | 서버 |
| 인터넷 브라우저 -> | (POST방식) http://hello.com -> | 서버 |
- GET 방식
GET 방식은 URI를 통해 데이터를 전달하기 때문에 같은 URI를 전달하면 서버에는 항상 데이터를 같이 전달합니다. - POST 방식
GET 방식의 문제점을 해결하기 위해 POST 방식을 사용하는데 만약 100줄 그 이상 천 줄, 만 줄이 넘는 블로그 글을 작성하고 데이터를 보내게 되면 전체 주소가 매우 길어지게 되어 브라우저마다 URI의 길이를 제한해야 한다. 또한 로그인의 경우 GET 파라미터를 통해 사용자의 아이디와 비밀번호가 노출됩니다. (hello.com/login?username=내 아이디&password=내 비밀번호)
따라서 이와 같은 문제를 해결하기 위해 눈에 보이지 않는 POST 방식을 사용합니다. - REST API
REST는 API를 통해 정보의 CRUD(Create 생성, Read 읽기, Update 갱신, Delete 삭제)가 목적입니다.
이러한 REST API는 GET과 POST 방식의 확장된 개념으로 입니다. GET이라는 메서드 이름에서 알 수 있듯 데이터를 가져올 때 GET을 사용하고 서버에 어떠한 값이나 상태를 변경하기 위해 POST를 주로 사용하는데 REST API는 이러한 POST의 개념을 더 세분화하여 PUT과 DELETE라는 기능을 추가하여 사용합니다.
| METHOD | 설명 |
| GET | GET를 통해 해당 리소스를 조회하고 해당 도큐먼트에 대한 자세한 정보를 가져온다. |
| POST | POST를 통해 해당 URI를 요청하면 리소스를 생성 |
| PUT | PUT를 통해 해당 리소스를 수정 |
| DELETE | DELETE를 통해 리소스를 삭제 |
REST란?
REST(Representational State Transfer)는 웹 상에서 데이터를 주고받는 방식 중 하나입니다. 웹의 원칙과 규칙을 따르는 아키텍처 스타일이라고 할 수 있어요. REST는 웹의 기본 원리인 HTTP(웹 브라우저가 웹 서버와 소통하는 방법)를 활용합니다. REST의 핵심 개념은 자원(Resource)을 URL로 나타내고, 이 자원에 대해 표준 HTTP 메서드(GET, POST, PUT, DELETE 등)를 사용하여 작업을 수행한다는 것입니다.
API란?
API(Application Programming Interface)는 소프트웨어끼리 서로 소통할 수 있게 해주는 매개체입니다. 예를 들어, 스마트폰의 날씨 앱이 기상청의 데이터를 가져올 때, 날씨 앱과 기상청의 시스템은 API를 통해 데이터를 주고받습니다. API는 일종의 규칙이나 약속으로, "이렇게 요청하면, 저렇게 응답할게"라는 식의 통신 규약입니다.
REST API란?
REST API는 REST 원칙을 따르는 API입니다. RESTful 하게 설계된 API는 자원을 URL로 표현하고, HTTP 메서드를 사용하여 자원에 대한 작업을 수행합니다. 예를 들어, 도서 정보를 다루는 REST API가 있다면, 다음과 같은 작업이 가능합니다:
- GET: 특정 도서의 정보를 가져오기 (조회)
- URL: https://api.example.com/books/1
- 설명: books라는 자원에서 ID가 1인 도서 정보를 가져옴
- POST: 새로운 도서 정보 추가하기 (생성)
- URL: https://api.example.com/books
- 설명: books라는 자원에 새로운 도서를 추가함
- PUT: 특정 도서 정보 수정하기 (수정)
- URL: https://api.example.com/books/1
- 설명: books라는 자원에서 ID가 1인 도서 정보를 수정함
- DELETE: 특정 도서 정보 삭제하기 (삭제)
- URL: https://api.example.com/books/1
- 설명: books라는 자원에서 ID가 1인 도서 정보를 삭제함
요약
- REST는 웹에서 데이터를 주고받는 방식입니다.
- API는 소프트웨어 간의 소통을 돕는 인터페이스입니다.
- REST API는 REST 원칙을 따르는 API로, URL과 HTTP 메서드를 사용하여 자원을 관리합니다.
REST API를 음식 배달 서비스에 비유한다면, 각 음식점은 자원(Resource)이고, 음식 주문은 HTTP 메서드라고 할 수 있습니다.
- GET: 메뉴판을 보고 음식 정보를 얻음 (조회)
- POST: 새로운 주문을 넣음 (생성)
- PUT: 기존 주문 내용을 변경함 (수정)
- DELETE: 주문을 취소함 (삭제)
파이썬 웹 크롤링
웹 크롤링(Crawling) 또는 웹 스크래핑(Scraping)은 웹페이지를 원본 그대로 불러와 웹페이지 내에 있는 데이터를 추출하는 기술이다.
웹 데이터를 크롤링하기 위해서는 웹소켓을 이용하여 원하는 웹사이트에 연결 요청을 해야 하는데 연결 요청의 응답으로 웹 서버가 응답을 보내면 보통 HTML이나 JSON 형식으로 반환을 합니다. 이렇게 반환된 데이터를 BeautifulSoup로 파싱 하는 것을 크롤링이라고 합니다.
날씨 웹페이지 가져오기
from bs4 import BeautifulSoup as bs
import requests
# 특정 도시의 날씨 페이지 URL 설정 (예: 서울)
url = "https://weather.com/weather/today/l/37.57,126.98"
# 페이지 요청 및 응답 받기
response = requests.get(url)
# BeautifulSoup으로 파싱
soup = bs(response.text, 'html.parser')
# 현재 온도와 날씨 상태를 담고 있는 요소 찾기
current_temp = soup.find('span', class_='CurrentConditions--tempValue--MHmYY')
current_condition = soup.find('div', class_='CurrentConditions--phraseValue--mZC_p')
if current_temp and current_condition:
print(f"Current Temperature: {current_temp.get_text(strip=True)}")
print(f"Current Condition: {current_condition.get_text(strip=True)}")
else:
print("Could not find weather information")
-------------------------------
Current Temperature: 78°
Current Condition: Cloudy
'Python > 빅데이터 분석과 머신러닝' 카테고리의 다른 글
| #4 데이터 보기(판다스) (0) | 2024.07.17 |
|---|---|
| #6 데이터 탐색 (0) | 2024.07.14 |
| #5 데이터 클렌징 (1) | 2024.07.14 |
| #2 파이썬 데이터 (1) | 2024.07.03 |
| #1 빅데이터와 인공지능(머신러닝) (1) | 2024.07.03 |